Back to Courses



Machine Learning Courses - Page 41
Showing results 401-410 of 485
Reinforcement Learning for Trading Strategies
In the final course from the Machine Learning for Trading specialization, you will be introduced to reinforcement learning (RL) and the benefits of using reinforcement learning in trading strategies. You will learn how RL has been integrated with neural networks and review LSTMs and how they can be applied to time series data. By the end of the course, you will be able to build trading strategies using reinforcement learning, differentiate between actor-based policies and value-based policies, and incorporate RL into a momentum trading strategy.
To be successful in this course, you should have advanced competency in Python programming and familiarity with pertinent libraries for machine learning, such as Scikit-Learn, StatsModels, and Pandas. Experience with SQL is recommended. You should have a background in statistics (expected values and standard deviation, Gaussian distributions, higher moments, probability, linear regressions) and foundational knowledge of financial markets (equities, bonds, derivatives, market structure, hedging).
Intro to Time Series Analysis in R
In this 2 hour long project-based course, you will learn the basics of time series analysis in R. By the end of this project, you will understand the essential theory for time series analysis and have built each of the major model types (Autoregressive, Moving Average, ARMA, ARIMA, and decomposition) on a real world data set to forecast the future. We will go over the essential packages and functions in R as well to make time series analysis easy.
Build, Train, and Deploy ML Pipelines using BERT
In the second course of the Practical Data Science Specialization, you will learn to automate a natural language processing task by building an end-to-end machine learning pipeline using Hugging Face’s highly-optimized implementation of the state-of-the-art BERT algorithm with Amazon SageMaker Pipelines. Your pipeline will first transform the dataset into BERT-readable features and store the features in the Amazon SageMaker Feature Store. It will then fine-tune a text classification model to the dataset using a Hugging Face pre-trained model, which has learned to understand the human language from millions of Wikipedia documents. Finally, your pipeline will evaluate the model’s accuracy and only deploy the model if the accuracy exceeds a given threshold.
Practical data science is geared towards handling massive datasets that do not fit in your local hardware and could originate from multiple sources. One of the biggest benefits of developing and running data science projects in the cloud is the agility and elasticity that the cloud offers to scale up and out at a minimum cost.
The Practical Data Science Specialization helps you develop the practical skills to effectively deploy your data science projects and overcome challenges at each step of the ML workflow using Amazon SageMaker. This Specialization is designed for data-focused developers, scientists, and analysts familiar with the Python and SQL programming languages and want to learn how to build, train, and deploy scalable, end-to-end ML pipelines - both automated and human-in-the-loop - in the AWS cloud.
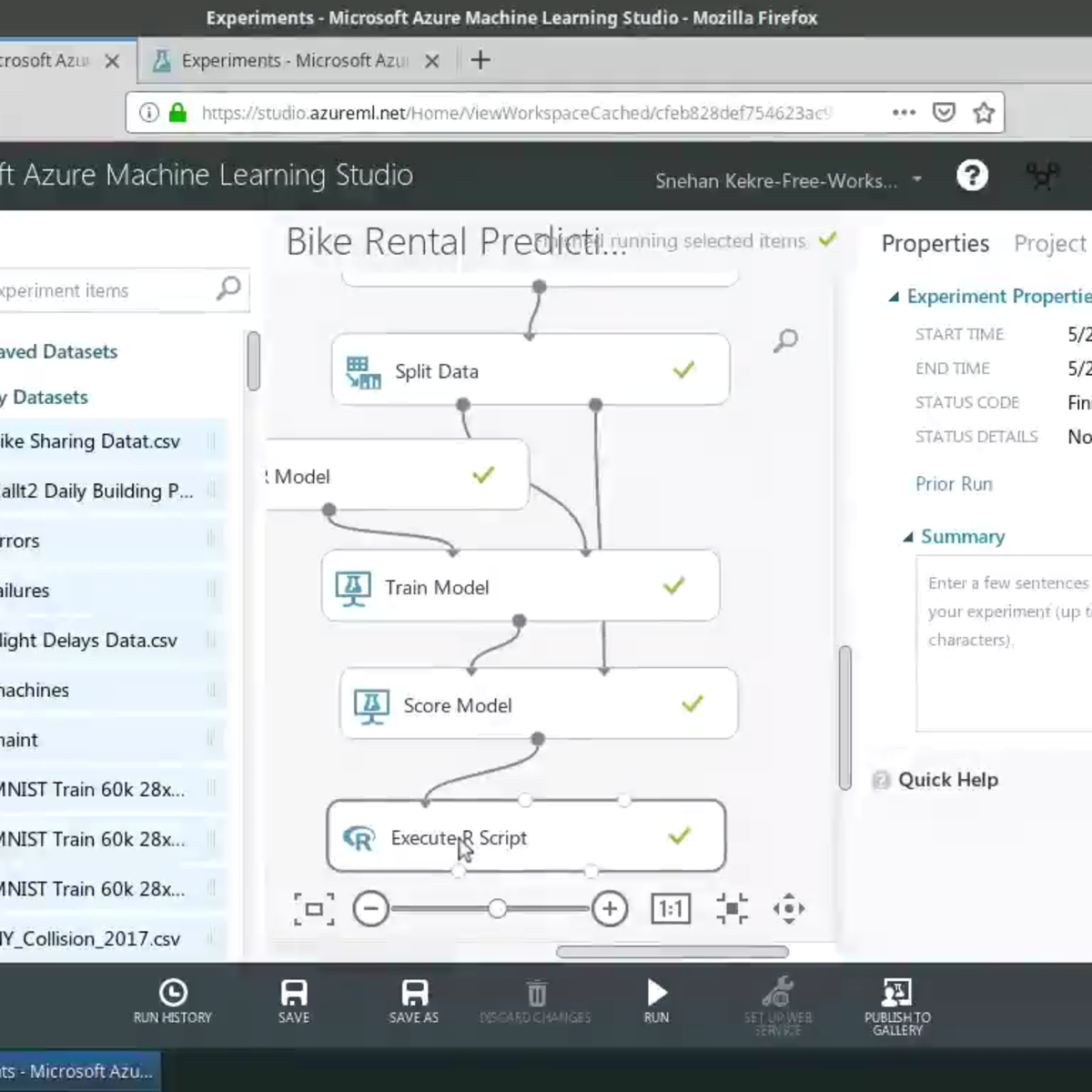
Build Random Forests in R with Azure ML Studio
In this project-based course you will learn to perform feature engineering and create custom R models on Azure ML Studio, all without writing a single line of code! You will build a Random Forests model in Azure ML Studio using the R programming language. The data to be used in this course is the Bike Sharing Dataset. The dataset contains the hourly and daily count of rental bikes between years 2011 and 2012 in Capital bikeshare system with the corresponding weather and seasonal information. Using the information from the dataset, you can build a model to predict the number of bikes rented during certain weather conditions. You will leverage the Execute R Script and Create R Model modules to run R scripts from the Azure ML Studio experiment perform feature engineering.
This is the fourth course in this series on building machine learning applications using Azure Machine Learning Studio. I highly encourage you to take the first course before proceeding. It has instructions on how to set up your Azure ML account with $200 worth of free credit to get started with running your experiments!
This course runs on Coursera's hands-on project platform called Rhyme. On Rhyme, you do projects in a hands-on manner in your browser. You will get instant access to pre-configured cloud desktops containing all of the software and data you need for the project. Everything is already set up directly in your internet browser so you can just focus on learning. For this project, you’ll get instant access to a cloud desktop with Python, Jupyter, and scikit-learn pre-installed.
Notes:
- You will be able to access the cloud desktop 5 times. However, you will be able to access instructions videos as many times as you want.
- This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Running Distributed TensorFlow using Vertex AI
This is a self-paced lab that takes place in the Google Cloud console. In this lab, you will use TensorFlow's distribution strategies and the Vertex AI platform to train and deploy a custom TensorFlow image classification model to classify an image classification dataset.
ML Parameters Optimization: GridSearch, Bayesian, Random
Hello everyone and welcome to this new hands-on project on Machine Learning hyperparameters optimization. In this project, we will optimize machine learning regression models parameters using several techniques such as grid search, random search and Bayesian optimization. Hyperparameter optimization is a key step in developing machine learning models and it works by fine tuning ML models so they can optimally perform on a given dataset.
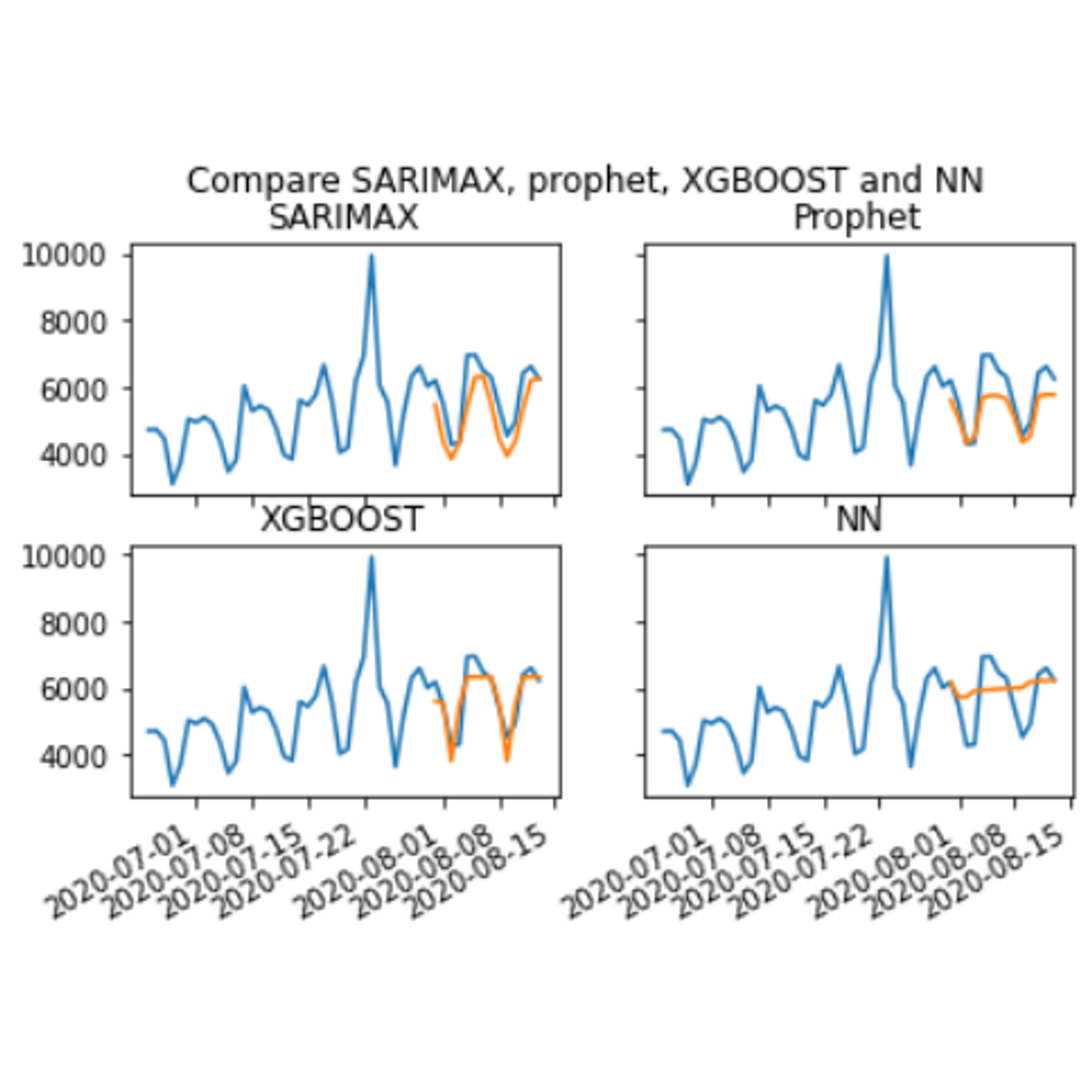
Compare time series predictions of COVID-19 deaths
By the end of this project, you will learn how to perform the entire time series analysis workflow for the daily COVID-19 deaths. This workflow includes the following steps: how to examine time series data, prepare the data for analysis, train different models and test their performance, and finally use the models to forecast into the future. You will learn how to visualize data using the matplotlib library, extract features from a time series data set, and perform data splitting and normalization. You will create time series analysis models using the python programming language. You will create and train four time series models: SARIMAX, Facebook prophet, neural networks and XGBOOST.
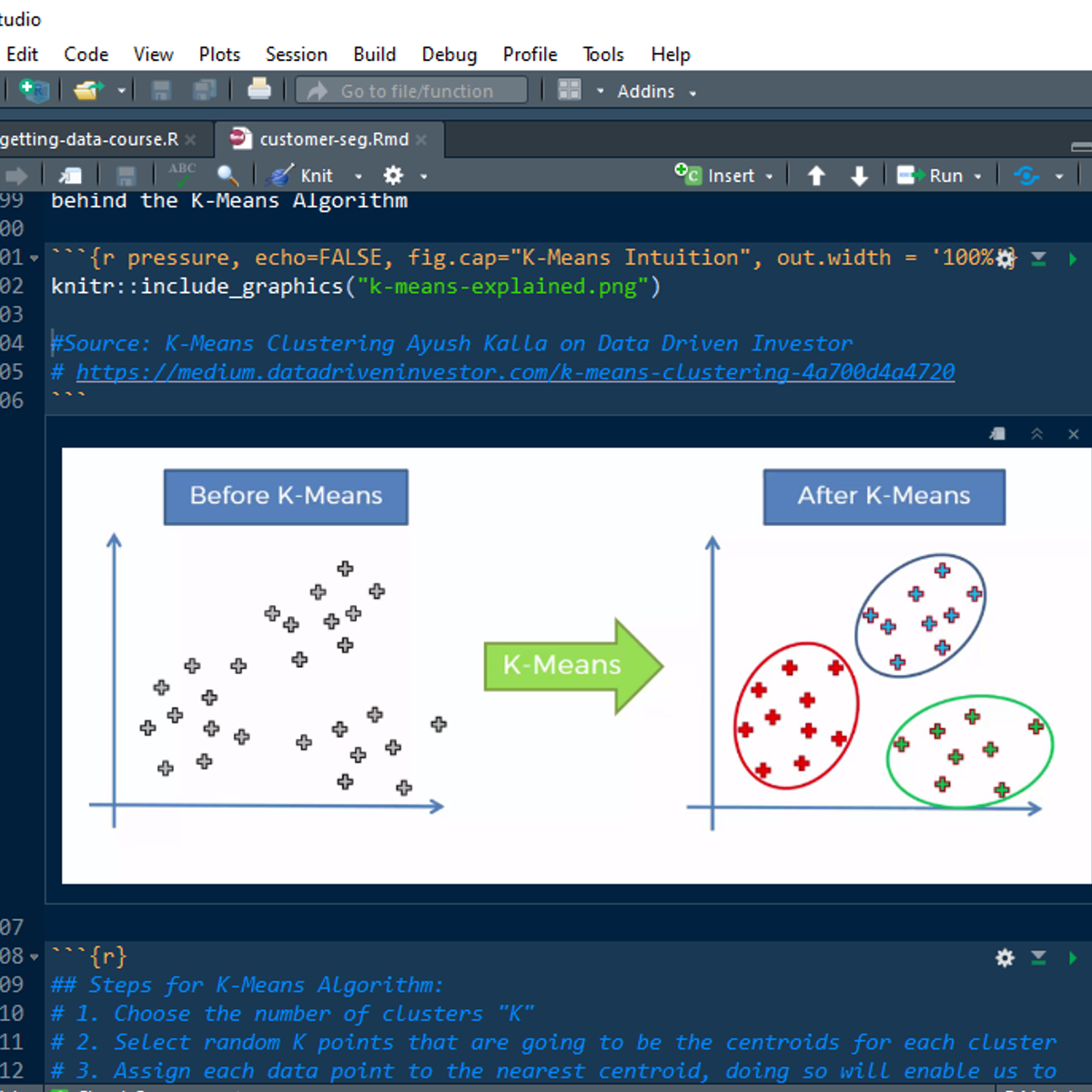
Customer Segmentation using K-Means Clustering in R
Welcome to this project-based course, Customer Segmentation using K-Means Clustering in R. In this project, you will learn how to perform customer market segmentation on mall customers data using different R packages.
By the end of this 2-and-a-half-hour long project, you will understand how to get the mall customers data into your RStudio workspace and explore the data. By extension, you will learn how to use the ggplot2 package to render beautiful plots of the data. Also, you will learn how to get the optimal number of clusters for the customers' segments and use K-Means to create distinct groups of customers based on their characteristics. Finally, you will learn how to use the R markdown file to organise your work and how to knit your code into an HTML document for publishing.
Although you do not need to be a data analyst expert or data scientist to succeed in this guided project, it requires a basic knowledge of using R, especially writing R syntaxes. Therefore, to complete this project, you must have prior experience with using R. If you are not familiar with working with using R, please go ahead to complete my previous project titled: “Getting Started with R”. It will hand you the needed knowledge to go ahead with this project on Customer Segmentation. However, if you are comfortable with working with R, please join me on this beautiful ride! Let’s get our hands dirty!
Data Science Capstone
The capstone project class will allow students to create a usable/public data product that can be used to show your skills to potential employers. Projects will be drawn from real-world problems and will be conducted with industry, government, and academic partners.
Learn C++ Functions
In this 1-hour long project-based course, you will (learn and understand C++ functions, Develop console applications using C++ functions).
C++ is a great programming language and rich in functions.
We will learn and understand C++ functions , mainly we focus on user defined functions and by the end of this project you will be able to create basic console applications using C++ functions.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Popular Internships and Jobs by Categories
Find Jobs & Internships
Browse





© 2024 BoostGrad | All rights reserved