Back to Courses








Machine Learning Courses - Page 42
Showing results 411-420 of 485
Effectively Dealing with Imbalance Classes
In this 2 hour guided project you will learn how to deal with imbalance classification problems in a profound manner, applying several resampling strategies and visualizing the effects of resampling on imbalance classification dataset.
Note: This project works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Building AI Applications with Watson APIs
A learner will be able to write an application that leverages multiple Watson AI services (Discovery, Speech to Text, Assistant, and Text to Speech). By the end of the course, they’ll learn best practices of combining Watson services, and how they can build interactive information retrieval systems with Discovery + Assistant.
Industrial IoT Fundamentals on AWS
Proficient technologists working on the Industrial IoT vertical use lots of technologies and methods to control, manage and get information from the IoT devices. So, there are assembly lines and industrial aspects that needs to take into consideration when talking about IoT when used in an industrial scale.
The story we are going to tell is about an individual who is new to that industry and got hired by a company who is planning to adopt to Industry 4.0 standards in next 3 years, the company is already familiar with some AWS services and already uses it for some other projects, such as their website and other workloads, so it makes sense for them to explore IIoT capabilities on AWS as well.
The company got into a multi-year partnership with AWS to help them transform and innovate, the company is also hiring lots of people with IoT and Cloud background, preferably with industrial exposure. As today, the company hired Engineers and Architects, but they have limited industrial experience. The company plans to up-skill their existing workforce of industrial engineers with Cloud knowledge to expand their resource pool over time, and due to this workforce, there is a clear knowledge gap on how to build an edge to cloud continuum from factories to cloud today.
The course will help individuals on being on par with what’s new, and best practices used to perform well in a given role like that.
Building Machine Learning Pipelines in PySpark MLlib
By the end of this project, you will learn how to create machine learning pipelines using Python and Spark, free, open-source programs that you can download. You will learn how to load your dataset in Spark and learn how to perform basic cleaning techniques such as removing columns with high missing values and removing rows with missing values. You will then create a machine learning pipeline with a random forest regression model. You will use cross validation and parameter tuning to select the best model from the pipeline. Lastly, you will evaluate your model’s performance using various metrics.
A pipeline in Spark combines multiple execution steps in the order of their execution. So rather than executing the steps individually, one can put them in a pipeline to streamline the machine learning process. You can save this pipeline, share it with your colleagues, and load it back again effortlessly.
Note: You should have a Gmail account which you will use to sign into Google Colab.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Introduction to Deep Learning
Deep Learning is the go-to technique for many applications, from natural language processing to biomedical. Deep learning can handle many different types of data such as images, texts, voice/sound, graphs and so on. This course will cover the basics of DL including how to build and train multilayer perceptron, convolutional neural networks (CNNs), recurrent neural networks (RNNs), autoencoders (AE) and generative adversarial networks (GANs). The course includes several hands-on projects, including cancer detection with CNNs, RNNs on disaster tweets, and generating dog images with GANs.
Prior coding or scripting knowledge is required. We will be utilizing Python extensively throughout the course. We recommend taking the two previous courses in the specialization, Introduction to Machine Learning: Supervised Learning and Unsupervised Algorithms in Machine Learning, but they are not required. College-level math skills, including Calculus and Linear Algebra, are needed. Some parts of the class will be relatively math intensive.
This course can be taken for academic credit as part of CU Boulder’s Master of Science in Data Science (MS-DS) degree offered on the Coursera platform. The MS-DS is an interdisciplinary degree that brings together faculty from CU Boulder’s departments of Applied Mathematics, Computer Science, Information Science, and others. With performance-based admissions and no application process, the MS-DS is ideal for individuals with a broad range of undergraduate education and/or professional experience in computer science, information science, mathematics, and statistics. Learn more about the MS-DS program at https://www.coursera.org/degrees/master-of-science-data-science-boulder.
Course logo image by Ryan Wallace on Unsplash.
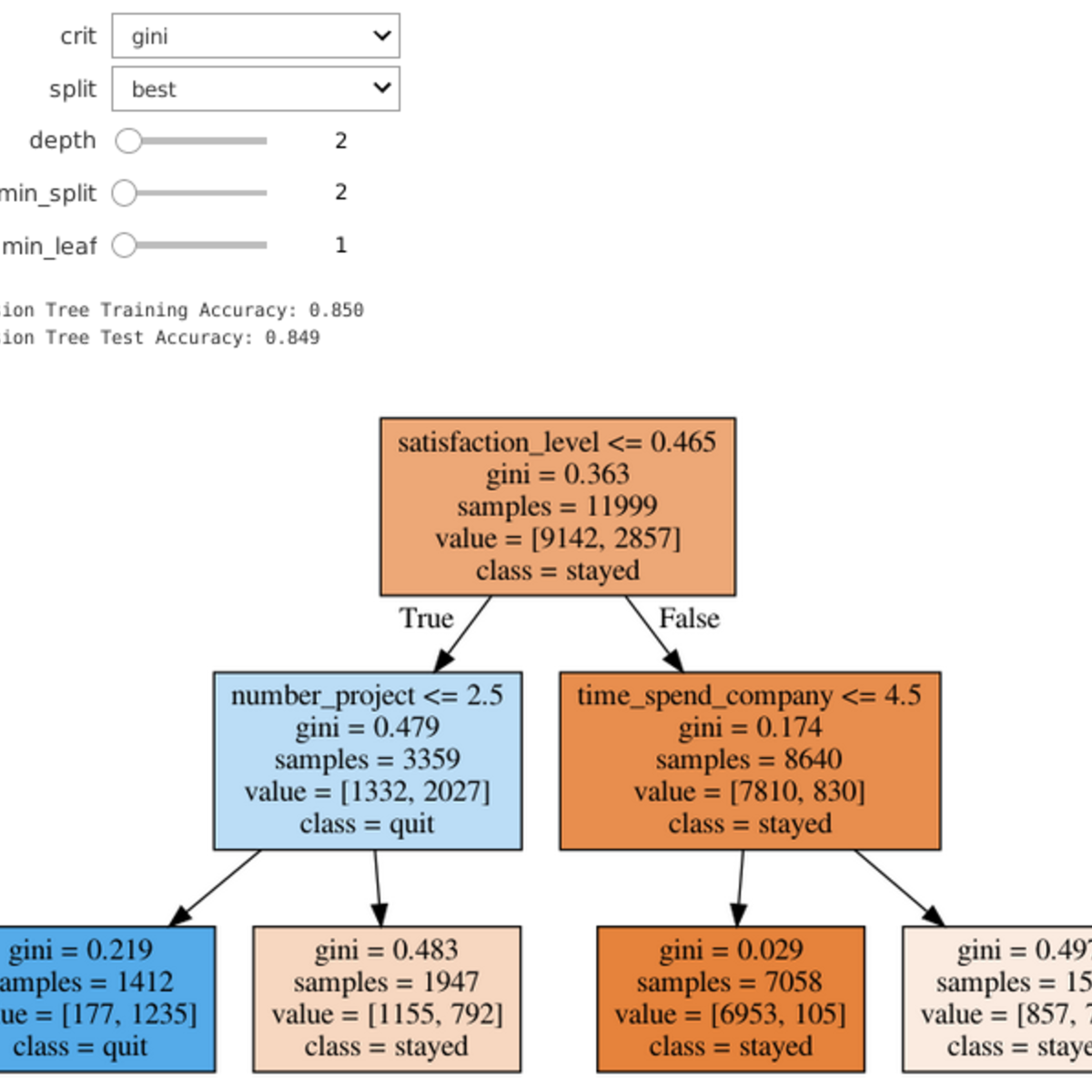
Predict Employee Turnover with scikit-learn
Welcome to this project-based course on Predicting Employee Turnover with Decision Trees and Random Forests using scikit-learn. In this project, you will use Python and scikit-learn to grow decision trees and random forests, and apply them to an important business problem. Additionally, you will learn to interpret decision trees and random forest models using feature importance plots. Leverage Jupyter widgets to build interactive controls, you can change the parameters of the models on the fly with graphical controls, and see the results in real time!
This course runs on Coursera's hands-on project platform called Rhyme. On Rhyme, you do projects in a hands-on manner in your browser. You will get instant access to pre-configured cloud desktops containing all of the software and data you need for the project. Everything is already set up directly in your internet browser so you can just focus on learning. For this project, you’ll get instant access to a cloud desktop with Python, Jupyter, and scikit-learn pre-installed.
Financial Regulation in Emerging Markets and the Rise of Fintech Companies
This course gives an overview of the changing regulatory environment since the 1997 Asian and 2008 global financial crisis. Following these two major crises, governments around the globe enacted a set of far-reaching new financial regulations that are aimed towards safeguarding financial stability. However, banks find it increasingly difficult to be profitable in this new regulatory environment. Technology, at the same time, has taken important leaps forward with the emergence of sophisticated models of artificial intelligence and the invention of the blockchain. These two developments fuel the emergence of fintech companies around the world.
This course discusses fintech regulation in emerging markets using case studies from China and South Africa. The course pays special attention to the socioeconomic environment in emerging markets, as well as to political risk as a major source of uncertainty for fintech entrepreneurs. Peer-to-peer lending and remittances are used as leading examples for fintech innovation in emerging markets.
TensorFlow for AI: Get to Know Tensorflow
This guided project course is part of the "Tensorflow for AI" series, and this series presents material that builds on the first course of DeepLearning.AI TensorFlow Developer Professional Certificate offered at Coursera, which will help learners reinforce their skills and build more projects with Tensorflow.
In this 1-hour long project-based course, you will get to know the basics and main components of Tensorflow through hands-on exercises, and you will learn how to define, compile and train a neural network with Tensorflow, and you will get a bonus practical deep learning project implemented with Tensorflow. By the end of this project, you will have developed a deeper understanding of Tensorflow, learned how to build a neural network with Tensorflow, and learned practically how to use Tensorflow to implement AI projects so that you can start building and applying scalable models to real-world problems.
This class is for learners who want to use Python for building AI models with TensorFlow, and for learners who are currently taking a basic deep learning course or have already finished a deep learning course and are searching for a practical deep learning with TensorFlow project. Also, this project provides learners with deeper knowledge about the basics of Tensorflow and its main components and improves their skills in Tensorflow which helps them in fulfilling their career goals by adding this project to their portfolios.
AI Workflow: Data Analysis and Hypothesis Testing
This is the second course in the IBM AI Enterprise Workflow Certification specialization. You are STRONGLY encouraged to complete these courses in order as they are not individual independent courses, but part of a workflow where each course builds on the previous ones.
In this course you will begin your work for a hypothetical streaming media company by doing exploratory data analysis (EDA). Best practices for data visualization, handling missing data, and hypothesis testing will be introduced to you as part of your work. You will learn techniques of estimation with probability distributions and extending these estimates to apply null hypothesis significance tests. You will apply what you learn through two hands on case studies: data visualization and multiple testing using a simple pipeline.
By the end of this course you should be able to:
1. List several best practices concerning EDA and data visualization
2. Create a simple dashboard in Watson Studio
3. Describe strategies for dealing with missing data
4. Explain the difference between imputation and multiple imputation
5. Employ common distributions to answer questions about event probabilities
6. Explain the investigative role of hypothesis testing in EDA
7. Apply several methods for dealing with multiple testing
Who should take this course?
This course targets existing data science practitioners that have expertise building machine learning models, who want to deepen their skills on building and deploying AI in large enterprises. If you are an aspiring Data Scientist, this course is NOT for you as you need real world expertise to benefit from the content of these courses.
What skills should you have?
It is assumed that you have completed Course 1 of the IBM AI Enterprise Workflow specialization and have a solid understanding of the following topics prior to starting this course: Fundamental understanding of Linear Algebra; Understand sampling, probability theory, and probability distributions; Knowledge of descriptive and inferential statistical concepts; General understanding of machine learning techniques and best practices; Practiced understanding of Python and the packages commonly used in data science: NumPy, Pandas, matplotlib, scikit-learn; Familiarity with IBM Watson Studio; Familiarity with the design thinking process.
Natural Language Processing in Microsoft Azure
Natural language processing supports applications that can see, hear, speak with, and understand users. Using text analytics, translation, and language understanding services, Microsoft Azure makes it easy to build applications that support natural language.
In this course, you will learn how to use the Text Analytics service for advanced natural language processing of raw text for sentiment analysis, key phrase extraction, named entity recognition, and language detection. You will learn how to recognize and synthesize speech by using Azure Cognitive Services. You will gain an understanding of how automated translation capabilities in an AI solution enable closer collaboration by removing language barriers. You will be introduced to the Language Understanding service, and shown how to create applications that understand language.
This course will help you prepare for Exam AI-900: Microsoft Azure AI Fundamentals. This is the fourth course in a five-course program that prepares you to take the AI-900 certification exam. This course teaches you the core concepts and skills that are assessed in the AI fundamentals exam domains.
This beginner course is suitable for IT personnel who are just beginning to work with Microsoft Azure and want to learn about Microsoft Azure offerings and get hands-on experience with the product. Microsoft Azure AI Fundamentals can be used to prepare for other Azure role-based certifications like Microsoft Azure Data Scientist Associate or Microsoft Azure AI Engineer Associate, but it is not a prerequisite for any of them.
This course is intended for candidates with both technical and non-technical backgrounds. Data science and software engineering experience is not required; however, some general programming knowledge or experience would be beneficial. To be successful in this course, you need to have basic computer literacy and proficiency in the English language. You should be familiar with basic computing concepts and terminology, general technology concepts, including machine learning and artificial intelligence concepts.
Popular Internships and Jobs by Categories
Find Jobs & Internships
Browse





© 2024 BoostGrad | All rights reserved