Back to Courses







Data Science Courses - Page 17
Showing results 161-170 of 1407
VM Migration: Introduction to StratoZone Assessments
This is a self-paced lab that takes place in the Google Cloud console. In this lab you'll learn how to assess an IT environment with StratoZone's scalable discovery.
Tools for Exploratory Data Analysis in Business
This course introduces several tools for processing business data to obtain actionable insight. The most important tool is the mind of the data analyst. Accordingly, in this course, you will explore what it means to have an analytic mindset. You will also practice identifying business problems that can be answered using data analytics. You will then be introduced to various software platforms to extract, transform, and load (ETL) data into tools for conducting exploratory data analytics (EDA). Specifically, you will practice using PowerBI, Alteryx, and RStudio to conduct the ETL and EDA processes.
The learning outcomes for this course include:
1. Development of an analytic mindset for approaching business problems.
2. The ability to appraise the value of datasets for addressing business problems using summary statistics and data visualizations.
3. The ability to competently operate business analytic software applications for exploratory data analysis.
Launching into Machine Learning
The course begins with a discussion about data: how to improve data quality and perform exploratory data analysis. We describe Vertex AI AutoML and how to build, train, and deploy an ML model without writing a single line of code. You will understand the benefits of Big Query ML. We then discuss how to optimize a machine learning (ML) model and how generalization and sampling can help assess the quality of ML models for custom training.
Supply Chain Optimization
Optimization is an important piece of an agile supply chain. In this course, we will explore the components of optimization and how to set up an optimization problem in Excel. We will also practice capacity and resource optimization and explore examples of both in the supply chain. Building off of our optimization practice, we will next learn how to use a Monte Carlo simulation to make the least risky decision in uncertain supply chain situations. Finally, we will combine our skills from this and the previous two courses to build a demand and inventory snapshot and optimize it, using a Monte Carlo simulation, to mitigate risks in the supply chain.
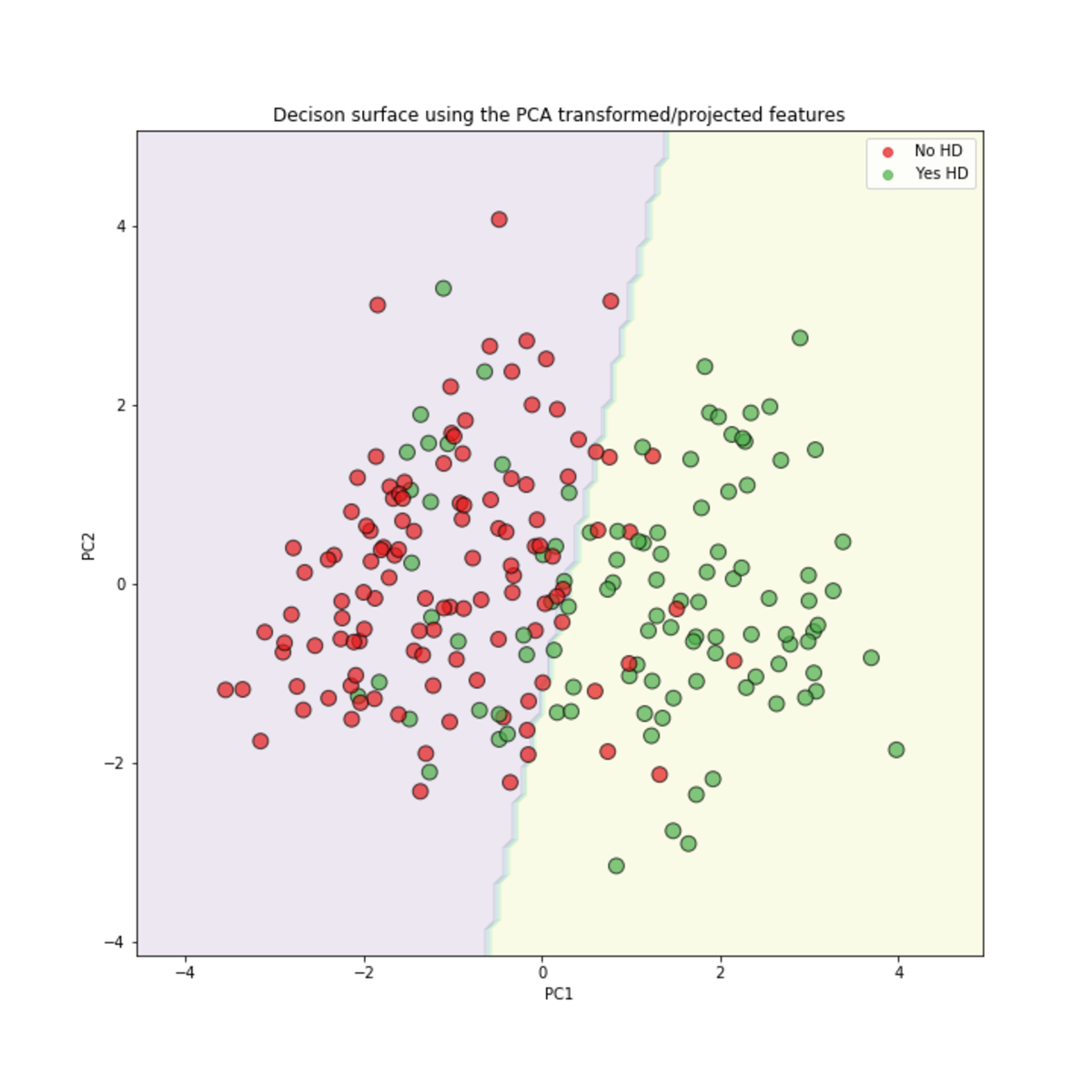
Support Vector Machines in Python, From Start to Finish
In this lesson we will built this Support Vector Machine for classification using scikit-learn and the Radial Basis Function (RBF) Kernel. Our training data set contains continuous and categorical data from the UCI Machine Learning Repository to predict whether or not a patient has heart disease.
This course runs on Coursera's hands-on project platform called Rhyme. On Rhyme, you do projects in a hands-on manner in your browser. You will get instant access to pre-configured cloud desktops containing all of the software and data you need for the project. Everything is already set up directly in your Internet browser so you can just focus on learning. For this project, you’ll get instant access to a cloud desktop with (e.g. Python, Jupyter, and Tensorflow) pre-installed.
Prerequisites:
In order to be successful in this project, you should be familiar with programming in Python and the concepts behind Support Vector Machines, the Radial Basis Function, Regularization, Cross Validation and Confusion Matrices.
Notes:
- You will be able to access the cloud desktop 5 times. However, you will be able to access instructions videos as many times as you want.
- This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Exploratory Data Analysis for Machine Learning
This first course in the IBM Machine Learning Professional Certificate introduces you to Machine Learning and the content of the professional certificate. In this course you will realize the importance of good, quality data. You will learn common techniques to retrieve your data, clean it, apply feature engineering, and have it ready for preliminary analysis and hypothesis testing.
By the end of this course you should be able to:
Retrieve data from multiple data sources: SQL, NoSQL databases, APIs, Cloud
Describe and use common feature selection and feature engineering techniques
Handle categorical and ordinal features, as well as missing values
Use a variety of techniques for detecting and dealing with outliers
Articulate why feature scaling is important and use a variety of scaling techniques
Who should take this course?
This course targets aspiring data scientists interested in acquiring hands-on experience with Machine Learning and Artificial Intelligence in a business setting.
What skills should you have?
To make the most out of this course, you should have familiarity with programming on a Python development environment, as well as fundamental understanding of Calculus, Linear Algebra, Probability, and Statistics.
ANOVA and Experimental Design
This second course in statistical modeling will introduce students to the study of the analysis of variance (ANOVA), analysis of covariance (ANCOVA), and experimental design. ANOVA and ANCOVA, presented as a type of linear regression model, will provide the mathematical basis for designing experiments for data science applications. Emphasis will be placed on important design-related concepts, such as randomization, blocking, factorial design, and causality. Some attention will also be given to ethical issues raised in experimentation.
This course can be taken for academic credit as part of CU Boulder’s Master of Science in Data Science (MS-DS) degree offered on the Coursera platform. The MS-DS is an interdisciplinary degree that brings together faculty from CU Boulder’s departments of Applied Mathematics, Computer Science, Information Science, and others. With performance-based admissions and no application process, the MS-DS is ideal for individuals with a broad range of undergraduate education and/or professional experience in computer science, information science, mathematics, and statistics. Learn more about the MS-DS program at https://www.coursera.org/degrees/master-of-science-data-science-boulder.
Logo adapted from photo by Vincent Ledvina on Unsplash
Smart Analytics, Machine Learning, and AI on GCP
Incorporating machine learning into data pipelines increases the ability of businesses to extract insights from their data. This course covers several ways machine learning can be included in data pipelines on Google Cloud depending on the level of customization required. For little to no customization, this course covers AutoML. For more tailored machine learning capabilities, this course introduces Notebooks and BigQuery machine learning (BigQuery ML). Also, this course covers how to productionalize machine learning solutions using Vertex AI. Learners will get hands-on experience building machine learning models on Google Cloud using QwikLabs.
Exploratory Data Analysis in R
In this 1-hour long project-based course, you will learn how to do basic exploratory data analysis (EDA) in R, automate your EDA reports and learn advanced EDA tips
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
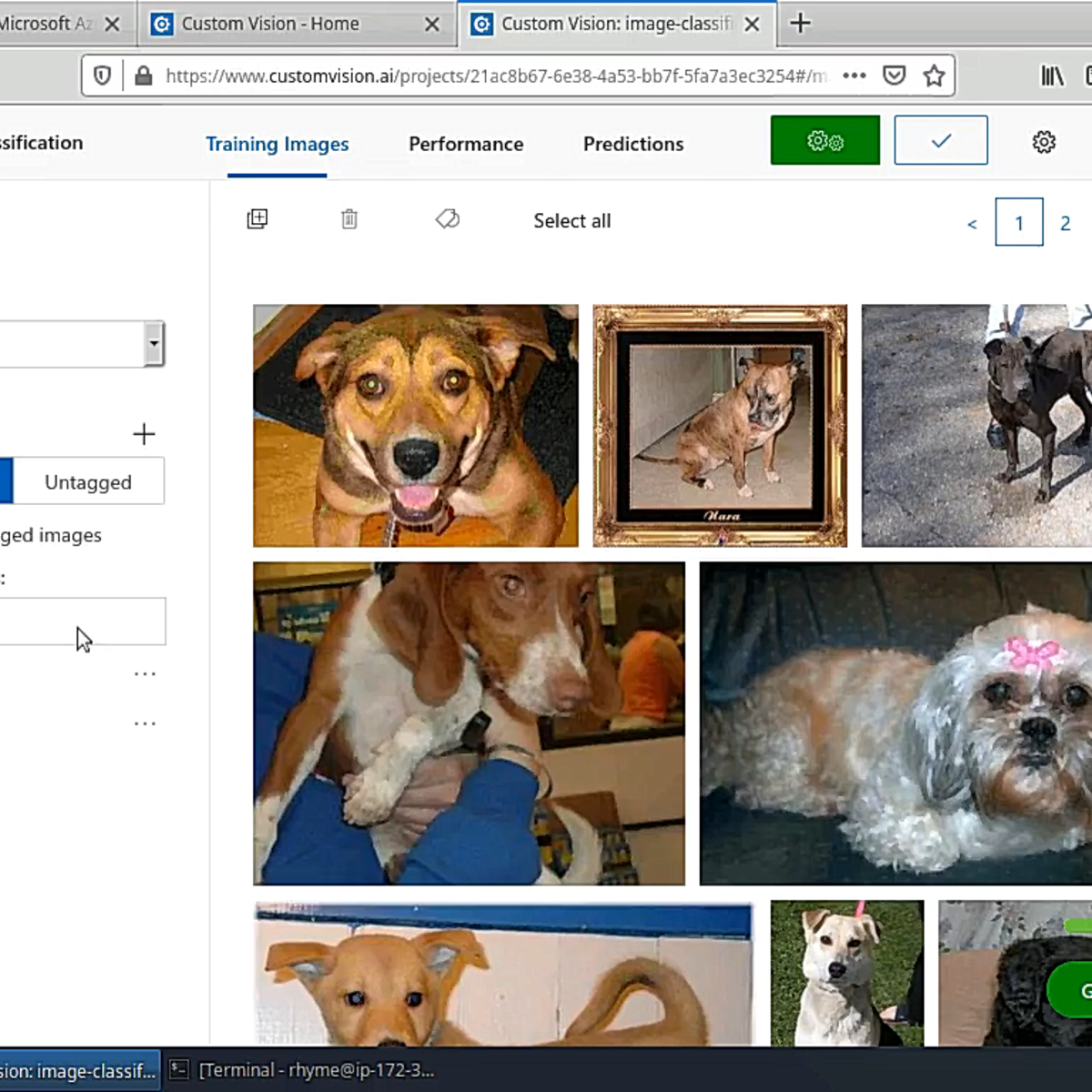
AutoML for Computer Vision with Microsoft Custom Vision
Welcome to this hands-on project on using Microsoft’s Custom Vision service for automated machine learning or AutoML as it’s popularly known. In this project, you are going to use Microsoft’s drag and drop tool to train your computer to recognize images of dogs and cats. We are going to do all of this without writing a single line of code! To take this guided-project, you do not need a background in computer science, machine learning or coding.
The only prerequisite for this project is that you have a Microsoft Azure account. If you don’t already have one, you will have to sign up for it.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Popular Internships and Jobs by Categories
Find Jobs & Internships
Browse





© 2024 BoostGrad | All rights reserved