Back to Courses






Data Science Courses - Page 16
Showing results 151-160 of 1407
FIFA20 Data Exploration using Python
By the end of this project, you will learn to use data Exploration techniques in order to uncover some initial patterns, insights and interesting points in your dataset. We are going to use a dataset consisting 5 CSV files, consisting of the data related to players in FIFA video game. We will clean and prepare it by dropping useless columns, calculating new features for our dataset and filling up the null values properly. and then we will start our exploration and we'll do some visualizations.
Note: This project works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Essential Causal Inference Techniques for Data Science
Data scientists often get asked questions related to causality: (1) did recent PR coverage drive sign-ups, (2) does customer support increase sales, or (3) did improving the recommendation model drive revenue? Supporting company stakeholders requires every data scientist to learn techniques that can answer questions like these, which are centered around issues of causality and are solved with causal inference.
In this project, you will learn the high level theory and intuition behind the four main causal inference techniques of controlled regression, regression discontinuity, difference in difference, and instrumental variables as well as some techniques at the intersection of machine learning and causal inference that are useful in data science called double selection and causal forests. These will help you rigorously answer questions like those above and become a better data scientist!
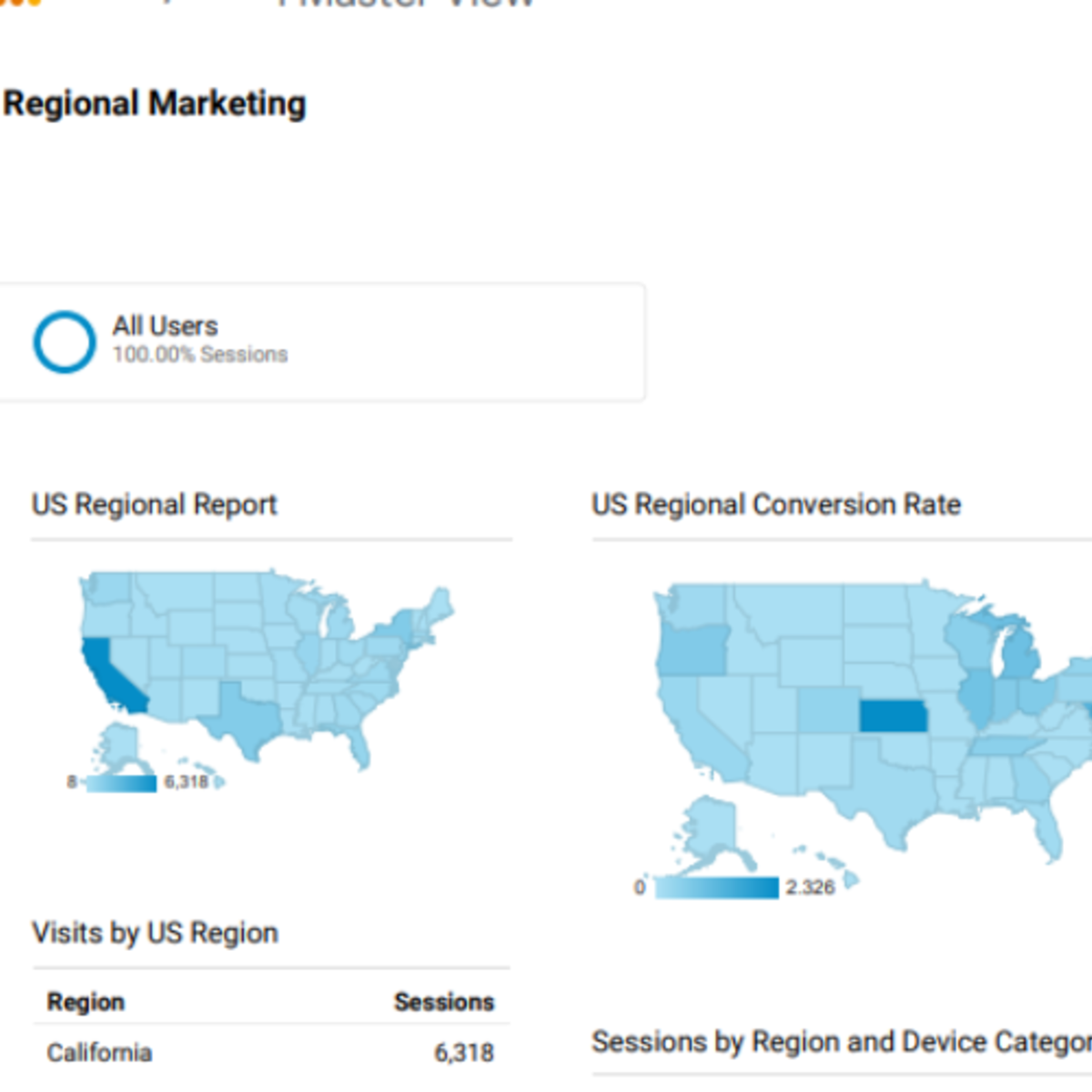
Building Custom Regional Reports with Google Analytics
In this 2 hours project you will learn how to build custom regional reports with Google Analytics. You will familiarize with Google Analytics and its usage, create a marketing custom regional dashboard with table and graph widgets, customize a standard geo report and scheduled the report you have designed to be sent monthly via email to a distributed regional marketing team.
Measuring and Maximizing Impact of COVID-19 Contact Tracing
This course aims to provide managers and developers of contact tracing programs guidance on the most important indicators of performance of a contact tracing program, and a tool that can be used to project the likely impact of improvements in specific indicators. Students who complete the course will be proficient in using the Contact Tracing Evaluation and Strategic Support Application (ConTESSA) to estimate the impact of their contact tracing program on transmission and strategizing about how to increase their program’s impact. A secondary audience for the course will be decision makers interested in knowing more about the characteristics of effective contact tracing programs, and strategies to improve.
The course is designed for individuals who are already leading contact tracing programs who have significant experience with epidemiology and public health. We strongly recommend completing this course on a laptop or a desktop rather than a phone as you’ll need to complete worksheets and open the course and the application simultaneously.
Predictive Modeling and Machine Learning with MATLAB
In this course, you will build on the skills learned in Exploratory Data Analysis with MATLAB and Data Processing and Feature Engineering with MATLAB to increase your ability to harness the power of MATLAB to analyze data relevant to the work you do.
These skills are valuable for those who have domain knowledge and some exposure to computational tools, but no programming background. To be successful in this course, you should have some background in basic statistics (histograms, averages, standard deviation, curve fitting, interpolation) and have completed courses 1 through 2 of this specialization.
By the end of this course, you will use MATLAB to identify the best machine learning model for obtaining answers from your data. You will prepare your data, train a predictive model, evaluate and improve your model, and understand how to get the most out of your models.
Customising your models with TensorFlow 2
Welcome to this course on Customising your models with TensorFlow 2!
In this course you will deepen your knowledge and skills with TensorFlow, in order to develop fully customised deep learning models and workflows for any application. You will use lower level APIs in TensorFlow to develop complex model architectures, fully customised layers, and a flexible data workflow. You will also expand your knowledge of the TensorFlow APIs to include sequence models.
You will put concepts that you learn about into practice straight away in practical, hands-on coding tutorials, which you will be guided through by a graduate teaching assistant. In addition there is a series of automatically graded programming assignments for you to consolidate your skills.
At the end of the course, you will bring many of the concepts together in a Capstone Project, where you will develop a custom neural translation model from scratch.
TensorFlow is an open source machine library, and is one of the most widely used frameworks for deep learning. The release of TensorFlow 2 marks a step change in the product development, with a central focus on ease of use for all users, from beginner to advanced level.
This course follows on directly from the previous course Getting Started with TensorFlow 2. The additional prerequisite knowledge required in order to be successful in this course is proficiency in the python programming language, (this course uses python 3), knowledge of general machine learning concepts (such as overfitting/underfitting, supervised learning tasks, validation, regularisation and model selection), and a working knowledge of the field of deep learning, including typical model architectures (MLP, CNN, RNN, ResNet), and concepts such as transfer learning, data augmentation and word embeddings.
Distributed Multi-worker TensorFlow Training on Kubernetes
This is a self-paced lab that takes place in the Google Cloud console.
In this hands-on lab you will explore using Google Cloud Kubernetes Engine and Kubeflow TFJob to scale out TensorFlow distributed training.
3D Data Visualization for Science Communication
This course is an introduction to 3D scientific data visualization, with an emphasis on science communication and cinematic design for appealing to broad audiences. You will develop visualization literacy, through being able to interpret/analyze (read) visualizations and create (write) your own visualizations.
By the end of this course, you will:
-Develop visualization literacy.
-Learn the practicality of working with spatial data.
-Understand what makes a scientific visualization meaningful.
-Learn how to create educational visualizations that maintain scientific accuracy.
-Understand what makes a scientific visualization cinematic.
-Learn how to create visualizations that appeal to broad audiences.
-Learn how to work with image-making software. (for those completing the Honors track)
Cloud Life Sciences: Variant Transforms Tool
This is a self-paced lab that takes place in the Google Cloud console. Use the Variant Transforms tool to transform and load VCF files from Cloud Storage into BigQuery.
Microsoft Azure Machine Learning
Machine learning is at the core of artificial intelligence, and many modern applications and services depend on predictive machine learning models. Training a machine learning model is an iterative process that requires time and compute resources. Automated machine learning can help make it easier. In this course, you will learn how to use Azure Machine Learning to create and publish models without writing code.
This course will help you prepare for Exam AI-900: Microsoft Azure AI Fundamentals. This is the second course in a five-course program that prepares you to take the AI-900 certification exam. This course teaches you the core concepts and skills that are assessed in the AI fundamentals exam domains. This beginner course is suitable for IT personnel who are just beginning to work with Microsoft Azure and want to learn about Microsoft Azure offerings and get hands-on experience with the product. Microsoft Azure AI Fundamentals can be used to prepare for other Azure role-based certifications like Microsoft Azure Data Scientist Associate or Microsoft Azure AI Engineer Associate, but it is not a prerequisite for any of them.
This course is intended for candidates with both technical and non-technical backgrounds. Data science and software engineering experience is not required; however, some general programming knowledge or experience would be beneficial. To be successful in this course, you need to have basic computer literacy and proficiency in the English language. You should be familiar with basic computing concepts and terminology, general technology concepts, including concepts of machine learning and artificial intelligence.
Popular Internships and Jobs by Categories
Find Jobs & Internships
Browse





© 2024 BoostGrad | All rights reserved