Back to Courses






Machine Learning Courses - Page 5
Showing results 41-50 of 485
NLP: Twitter Sentiment Analysis
In this hands-on project, we will train a Naive Bayes classifier to predict sentiment from thousands of Twitter tweets. This project could be practically used by any company with social media presence to automatically predict customer's sentiment (i.e.: whether their customers are happy or not). The process could be done automatically without having humans manually review thousands of tweets and customer reviews.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Introduction to Machine Learning
This course will provide you a foundational understanding of machine learning models (logistic regression, multilayer perceptrons, convolutional neural networks, natural language processing, etc.) as well as demonstrate how these models can solve complex problems in a variety of industries, from medical diagnostics to image recognition to text prediction. In addition, we have designed practice exercises that will give you hands-on experience implementing these data science models on data sets. These practice exercises will teach you how to implement machine learning algorithms with PyTorch, open source libraries used by leading tech companies in the machine learning field (e.g., Google, NVIDIA, CocaCola, eBay, Snapchat, Uber and many more).
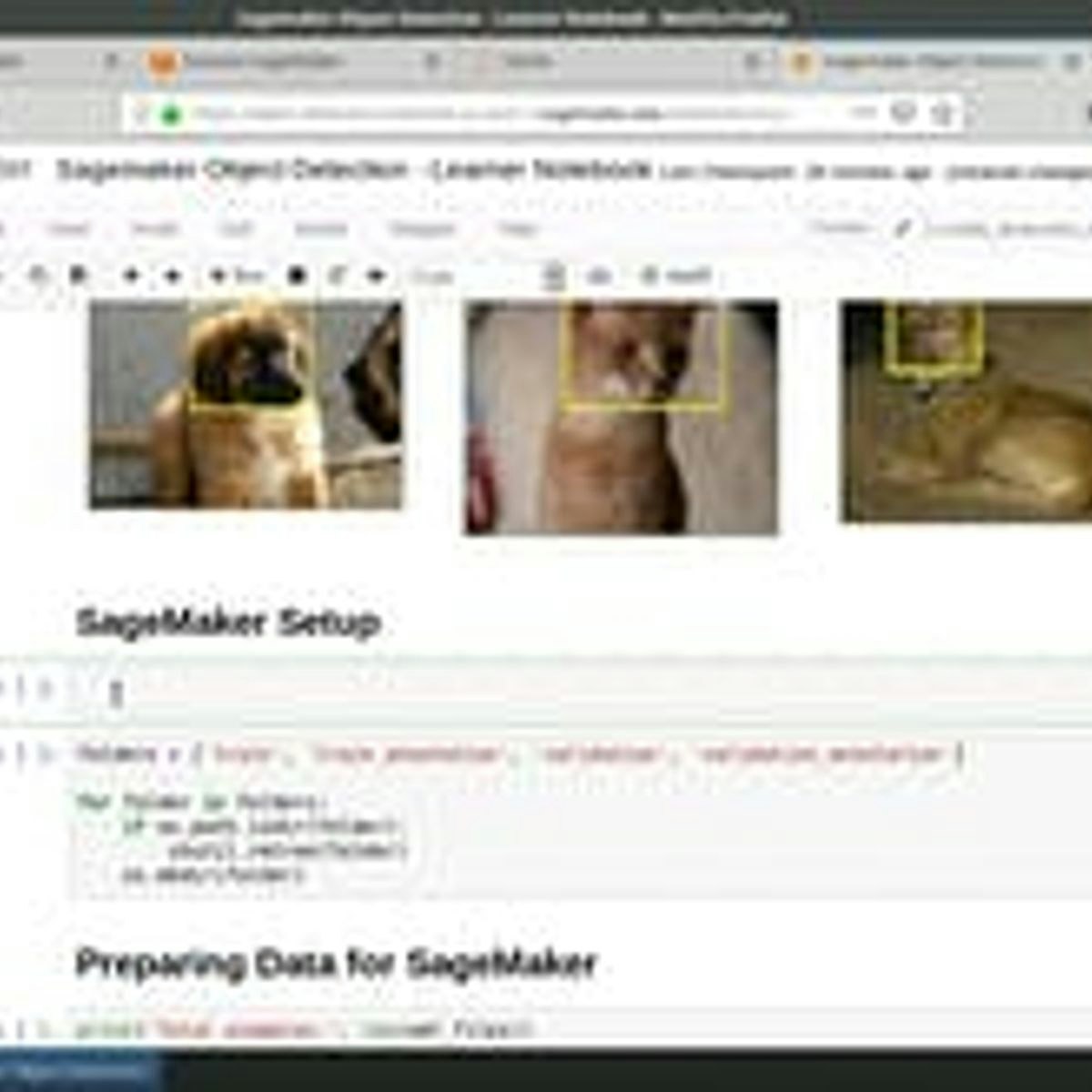
Object Detection with Amazon Sagemaker
Please note: You will need an AWS account to complete this course. Your AWS account will be charged as per your usage. Please make sure that you are able to access Sagemaker within your AWS account. If your AWS account is new, you may need to ask AWS support for access to certain resources. You should be familiar with python programming, and AWS before starting this hands on project. We use a Sagemaker P type instance in this project, and if you don't have access to this instance type, please contact AWS support and request access.
In this 2-hour long project-based course, you will learn how to train and deploy an object detector using Amazon Sagemaker. Sagemaker provides a number of machine learning algorithms ready to be used for solving a number of tasks. We will use the SSD Object Detection algorithm from Sagemaker to create, train and deploy a model that will be able to localize faces of dogs and cats from the popular IIIT-Oxford Pets Dataset.
Since this is a practical, project-based course, we will not dive in the theory behind deep learning based SSD or Object Detection, but will focus purely on training and deploying a model with Sagemaker. You will also need to have some experience with Amazon Web Services (AWS).
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Modeling Data in the Tidyverse
Developing insights about your organization, business, or research project depends on effective modeling and analysis of the data you collect. Building effective models requires understanding the different types of questions you can ask and how to map those questions to your data. Different modeling approaches can be chosen to detect interesting patterns in the data and identify hidden relationships.
This course covers the types of questions you can ask of data and the various modeling approaches that you can apply. Topics covered include hypothesis testing, linear regression, nonlinear modeling, and machine learning. With this collection of tools at your disposal, as well as the techniques learned in the other courses in this specialization, you will be able to make key discoveries from your data for improving decision-making throughout your organization.
In this specialization we assume familiarity with the R programming language. If you are not yet familiar with R, we suggest you first complete R Programming before returning to complete this course.
Fake News Detection with Machine Learning
In this hands-on project, we will train a Bidirectional Neural Network and LSTM based deep learning model to detect fake news from a given news corpus. This project could be practically used by any media company to automatically predict whether the circulating news is fake or not. The process could be done automatically without having humans manually review thousands of news related articles.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Applied Data Science for Data Analysts
In this course, you will develop your data science skills while solving real-world problems. You'll work through the data science process to and use unsupervised learning to explore data, engineer and select meaningful features, and solve complex supervised learning problems using tree-based models. You will also learn to apply hyperparameter tuning and cross-validation strategies to improve model performance.
NOTE: This is the third and final course in the Data Science with Databricks for Data Analysts Coursera specialization. To be successful in this course we highly recommend taking the first two courses in that specialization prior to taking this course. These courses are: Apache Spark for Data Analysts and Data Science Fundamentals for Data Analysts.
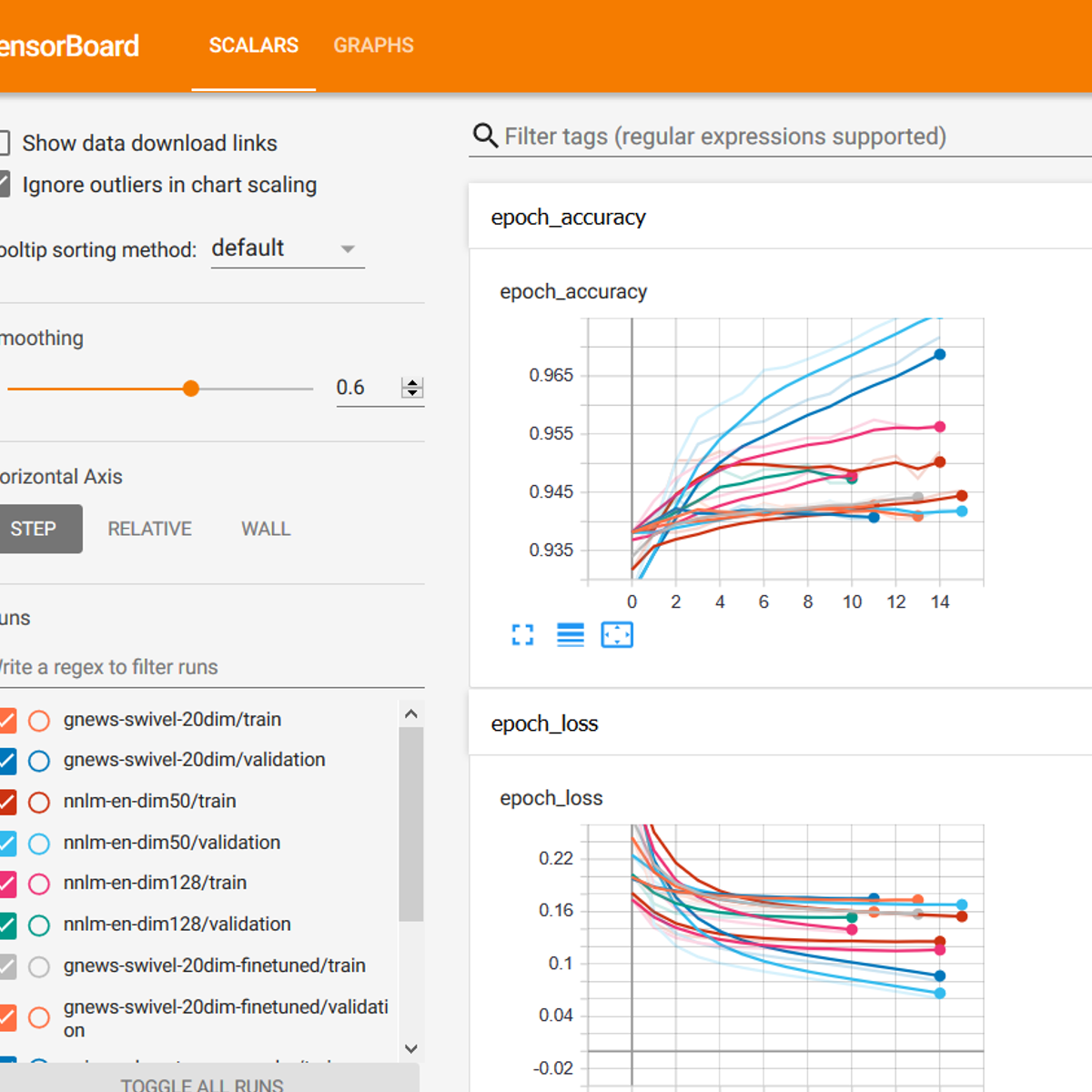
Transfer Learning for NLP with TensorFlow Hub
This is a hands-on project on transfer learning for natural language processing with TensorFlow and TF Hub. By the time you complete this project, you will be able to use pre-trained NLP text embedding models from TensorFlow Hub, perform transfer learning to fine-tune models on real-world data, build and evaluate multiple models for text classification with TensorFlow, and visualize model performance metrics with Tensorboard.
Prerequisites:
In order to successfully complete this project, you should be competent in the Python programming language, be familiar with deep learning for Natural Language Processing (NLP), and have trained models with TensorFlow or and its Keras API.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
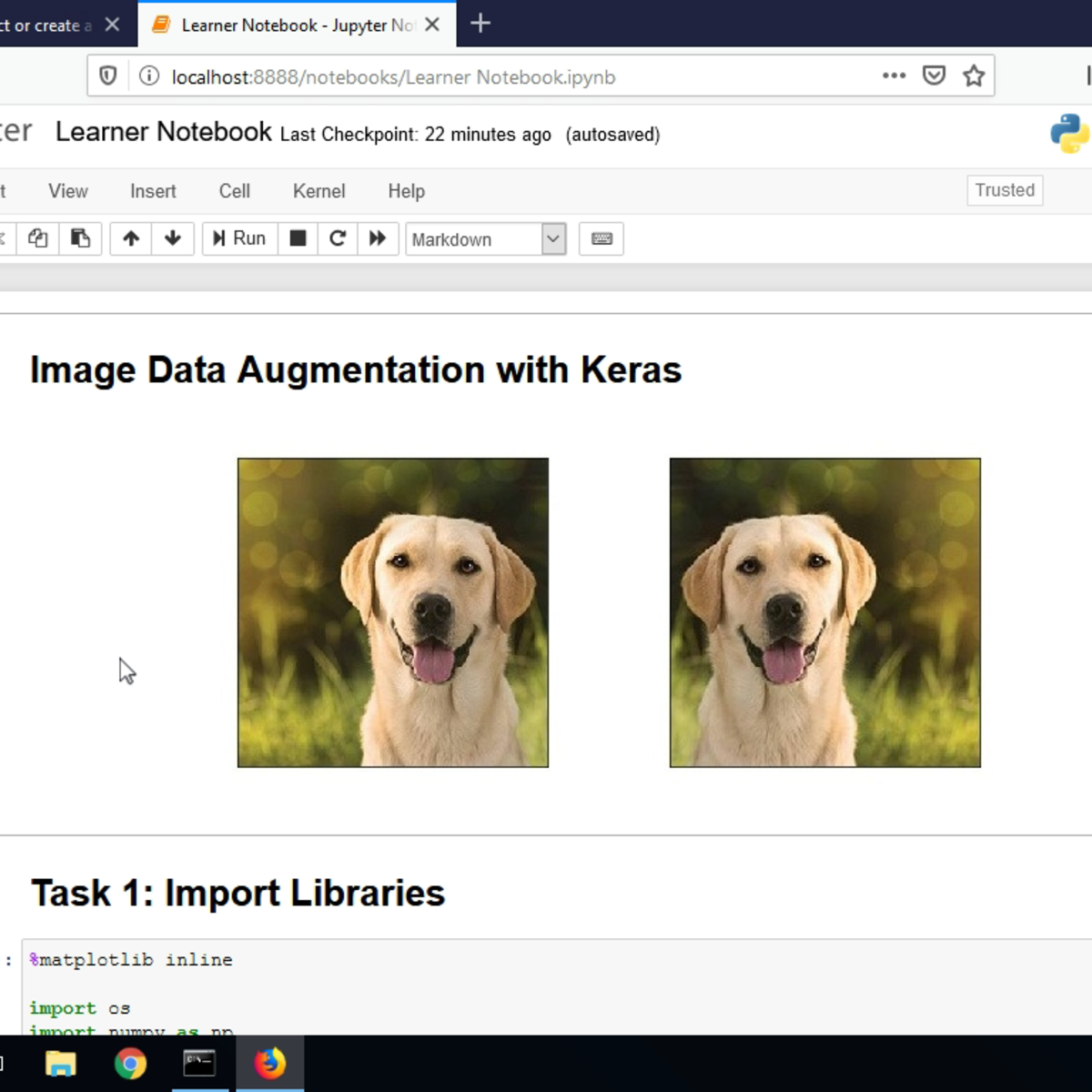
Image Data Augmentation with Keras
In this 1.5-hour long project-based course, you will learn how to apply image data augmentation in Keras. We are going to focus on using the ImageDataGenerator class from Keras’ image preprocessing package, and will take a look at a variety of options available in this class for data augmentation and data normalization.
Since this is a practical, project-based course, you will need to prior experience with Python programming, convolutional neural networks, and Keras with a TensorFlow backend.
Data augmentation is a technique used to create more examples, artificially, from an existing dataset. This is useful if your dataset is small and you want to increase the number of examples. Data augmentation can often solve over-fitting so that your model generalizes well after training. For images, a variety of augmentation can be applied to increase the number of examples.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Managing Machine Learning Projects with Google Cloud
Business professionals in non-technical roles have a unique opportunity to lead or influence machine learning projects. If you have questions about machine learning and want to understand how to use it, without the technical jargon, this course is for you. Learn how to translate business problems into machine learning use cases and vet them for feasibility and impact. Find out how you can discover unexpected use cases, recognize the phases of an ML project and considerations within each, and gain confidence to propose a custom ML use case to your team or leadership or translate the requirements to a technical team.
Classification with Transfer Learning in Keras
In this 1.5 hour long project-based course, you will learn to create and train a Convolutional Neural Network (CNN) with an existing CNN model architecture, and its pre-trained weights. We will use the MobileNet model architecture along with its weights trained on the popular ImageNet dataset. By using a model with pre-trained weights, and then training just the last layers on a new dataset, we can drastically reduce the training time required to fit the model to the new data . The pre-trained model has already learned to recognize thousands on simple and complex image features, and we are using its output as the input to the last layers that we are training.
In order to be successful in this project, you should be familiar with Python, Neural Networks, and CNNs.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Popular Internships and Jobs by Categories
Find Jobs & Internships
Browse





© 2024 BoostGrad | All rights reserved