
Back to Courses







Machine Learning Courses - Page 20
Showing results 191-200 of 485
Using TensorFlow with Amazon Sagemaker
Please note: You will need an AWS account to complete this course. Your AWS account will be charged as per your usage. Please make sure that you are able to access Sagemaker within your AWS account. If your AWS account is new, you may need to ask AWS support for access to certain resources. You should be familiar with python programming, and AWS before starting this hands on project. We use a Sagemaker P type instance in this project, and if you don't have access to this instance type, please contact AWS support and request access.
In this 2-hour long project-based course, you will learn how to train and deploy an image classifier created and trained with the TensorFlow framework within the Amazon Sagemaker ecosystem. Sagemaker provides a number of machine learning algorithms ready to be used for solving a number of tasks. However, it is possible to use Sagemaker for custom training scripts as well. We will use TensorFlow and Sagemaker's TensorFlow Estimator to create, train and deploy a model that will be able to classify images of dogs and cats from the popular Oxford IIIT Pet Dataset.
Since this is a practical, project-based course, we will not dive in the theory behind deep learning based image classification, but will focus purely on training and deploying a model with Sagemaker and TensorFlow. You will also need to have some experience with Amazon Web Services (AWS).
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Recommender Systems Capstone
This capstone project course for the Recommender Systems Specialization brings together everything you've learned about recommender systems algorithms and evaluation into a comprehensive recommender analysis and design project. You will be given a case study to complete where you have to select and justify the design of a recommender system through analysis of recommender goals and algorithm performance.
Learners in the honors track will focus on experimental evaluation of the algorithms against medium sized datasets. The standard track will include a mix of provided results and spreadsheet exploration.
Both groups will produce a capstone report documenting the analysis, the selected solution, and the justification for that solution.
Fundamentals of Machine Learning for Supply Chain
This course will teach you how to leverage the power of Python to understand complicated supply chain datasets. Even if you are not familiar with supply chain fundamentals, the rich data sets that we will use as a canvas will help orient you with several Pythonic tools and best practices for exploratory data analysis (EDA). As such, though all datasets are geared towards supply chain minded professionals, the lessons are easily generalizable to other use cases.
Introduction to Artificial Intelligence (AI)
In this course you will learn what Artificial Intelligence (AI) is, explore use cases and applications of AI, understand AI concepts and terms like machine learning, deep learning and neural networks. You will be exposed to various issues and concerns surrounding AI such as ethics and bias, & jobs, and get advice from experts about learning and starting a career in AI. You will also demonstrate AI in action with a mini project.
This course does not require any programming or computer science expertise and is designed to introduce the basics of AI to anyone whether you have a technical background or not.
Detect Labels, Faces, and Landmarks in Images with the Cloud Vision API
This is a self-paced lab that takes place in the Google Cloud console.
The Cloud Vision API lets you understand the content of an image by encapsulating powerful machine learning models in a simple REST API. In this lab you’ll send an image to the Cloud Vision API and have it identify objects, faces, and landmarks.
Classify Images of Cats and Dogs using Transfer Learning
This is a self-paced lab that takes place in the Google Cloud console.
TensorFlow is an end-to-end open source platform for machine learning. It has a comprehensive, flexible ecosystem of tools, libraries and community resources that lets researchers push the state-of-the-art in ML and developers easily build and deploy ML powered applications.
This lab uses transfer learning to train your machine. In transfer learning, when you build a new model to classify your original dataset, you reuse the feature extraction part and re-train the classification part with your dataset. This method uses less computational resources and training time. Deep learning from scratch can take days, but transfer learning can be done in short order.
Digital Thread: Components
This course will help you recognize how the "digital thread" is the backbone of the digital manufacturing and design (DM&D) transformation, turning manufacturing processes from paper-based to digital-based. You will have a working understanding of the digital thread – the stream that starts at product concept and continues to accumulate information and data throughout the product’s life cycle – and identify opportunities to leverage it.
Gain an understanding of how "the right information, in the right place, at the right time" should flow. This is one of the keys to unlocking the potential of a digital design process. Acknowledging this will enable you to be more involved in a product’s development cycle, and to help a company become more flexible.
Main concepts of this course will be delivered through lectures, readings, discussions and various videos.
This is the second course in the Digital Manufacturing & Design Technology specialization that explores the many facets of manufacturing’s “Fourth Revolution,” aka Industry 4.0, and features a culminating project involving creation of a roadmap to achieve a self-established DMD-related professional goal. To learn more about the Digital Manufacturing and Design Technology specialization, please watch the overview video by copying and pasting the following link into your web browser: https://youtu.be/wETK1O9c-CA
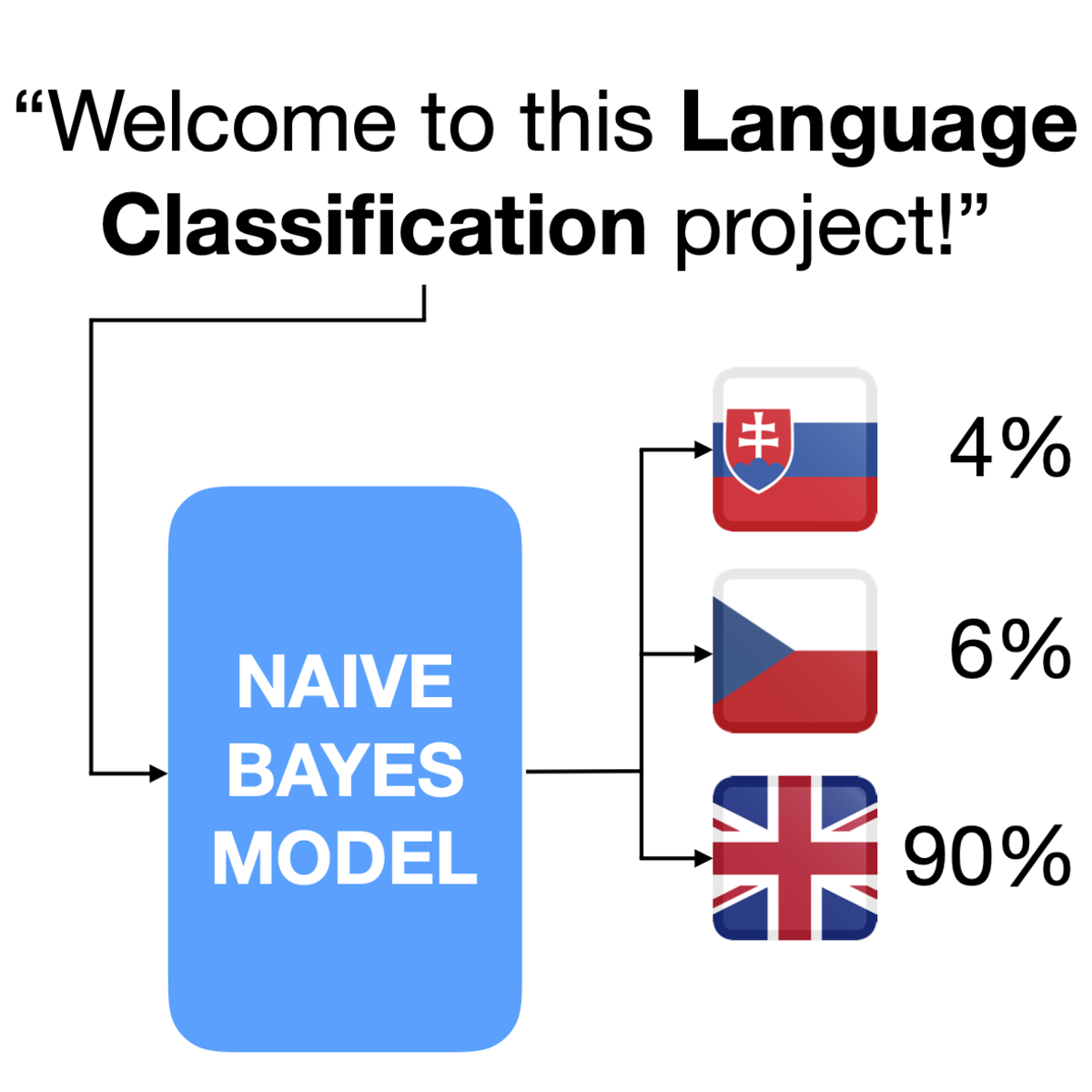
Language Classification with Naive Bayes in Python
In this 1-hour long project, you will learn how to clean and preprocess data for language classification. You will learn some theory behind Naive Bayes Modeling, and the impact that class imbalance of training data has on classification performance. You will learn how to use subword units to further mitigate the negative effects of class imbalance, and build an even better model.
Explore insights in text analysis using Azure Text Analytics
In this one-hour project, you will understand how Azure Text Analytics works and how you can use the power of Natual Language Processing, NLP, and Machine Learning to extract information and explore insights from text. You will learn how to use Azure Text Analytics to extract entities' sentiments, key phrases, and other elements from text like product reviews, understand how the results are organized, manipulate the data and generate a report to explore the insights.
Azure Text Analytics is a fully managed service, and it is one of the most powerful Natural Language Processing engines in the market, so you can get up and running quickly, without having to train models from scratch.
Once you're done with this project, you will be able to use Azure Text Analytics to extract, analyze and explore insights in your documents in just a few steps.
AI Workflow: Business Priorities and Data Ingestion
This is the first course of a six part specialization. You are STRONGLY encouraged to complete these courses in order as they are not individual independent courses, but part of a workflow where each course builds on the previous ones.
This first course in the IBM AI Enterprise Workflow Certification specialization introduces you to the scope of the specialization and prerequisites. Specifically, the courses in this specialization are meant for practicing data scientists who are knowledgeable about probability, statistics, linear algebra, and Python tooling for data science and machine learning. A hypothetical streaming media company will be introduced as your new client. You will be introduced to the concept of design thinking, IBMs framework for organizing large enterprise AI projects. You will also be introduced to the basics of scientific thinking, because the quality that distinguishes a seasoned data scientist from a beginner is creative, scientific thinking. Finally you will start your work for the hypothetical media company by understanding the data they have, and by building a data ingestion pipeline using Python and Jupyter notebooks.
By the end of this course you should be able to:
1. Know the advantages of carrying out data science using a structured process
2. Describe how the stages of design thinking correspond to the AI enterprise workflow
3. Discuss several strategies used to prioritize business opportunities
4. Explain where data science and data engineering have the most overlap in the AI workflow
5. Explain the purpose of testing in data ingestion
6. Describe the use case for sparse matrices as a target destination for data ingestion
7. Know the initial steps that can be taken towards automation of data ingestion pipelines
Who should take this course?
This course targets existing data science practitioners that have expertise building machine learning models, who want to deepen their skills on building and deploying AI in large enterprises. If you are an aspiring Data Scientist, this course is NOT for you as you need real world expertise to benefit from the content of these courses.
What skills should you have?
It is assumed you have a solid understanding of the following topics prior to starting this course: Fundamental understanding of Linear Algebra; Understand sampling, probability theory, and probability distributions; Knowledge of descriptive and inferential statistical concepts; General understanding of machine learning techniques and best practices; Practiced understanding of Python and the packages commonly used in data science: NumPy, Pandas, matplotlib, scikit-learn; Familiarity with IBM Watson Studio; Familiarity with the design thinking process.
Popular Internships and Jobs by Categories
Browse
© 2024 BoostGrad | All rights reserved