
Back to Courses







Machine Learning Courses - Page 21
Showing results 201-210 of 485
Deploy Bridgerton NLP SMS Text Generator
Welcome to the “Deploy Bridgerton NLP SMS Text Generator” guided project.
In this project, we will deploy an NLP text generator model that sends text messages of generated words to a phone number via SMS through a python Streamlit app. The model has been trained on quotes from Netflix's popular tv show "Bridgerton".
This project is an intermediate python project for anyone interested in learning about how to productionize natural language text generator models as a Streamlit app on Heroku and leveraging python modules to send SMS texts.
It requires preliminary knowledge on how to build and train NLP text generator models (as we will not be building or training models), how to utilize Git, and how to leverage multiple Python modules like the email and smtp modules. Learners would also need a Heroku account and some familiarity with the Python Streamlit module.
At the end of this project, learners will have a publicly available Streamlit web app that leverages natural language processing text generation to send generated Bridgerton quotes via SMS to a phone number.
Clinical Decision Support Systems - CDSS 4
Machine learning systems used in Clinical Decision Support Systems (CDSS) require further external validation, calibration analysis, assessment of bias and fairness. In this course, the main concepts of machine learning evaluation adopted in CDSS will be explained. Furthermore, decision curve analysis along with human-centred CDSS that need to be explainable will be discussed. Finally, privacy concerns of deep learning models and potential adversarial attacks will be presented along with the vision for a new generation of explainable and privacy-preserved CDSS.
Train Machine Learning Models
This course is designed for business professionals that wish to identify basic concepts that make up machine learning, test model hypothesis using a design of experiments and train, tune and evaluate models using algorithms that solve classification, regression and forecasting, and clustering problems.
To be successful in this course a learner should have a background in computing technology, including some aptitude in computer programming.
Fundamentals of Reinforcement Learning
Reinforcement Learning is a subfield of Machine Learning, but is also a general purpose formalism for automated decision-making and AI. This course introduces you to statistical learning techniques where an agent explicitly takes actions and interacts with the world. Understanding the importance and challenges of learning agents that make decisions is of vital importance today, with more and more companies interested in interactive agents and intelligent decision-making.
This course introduces you to the fundamentals of Reinforcement Learning. When you finish this course, you will:
- Formalize problems as Markov Decision Processes
- Understand basic exploration methods and the exploration/exploitation tradeoff
- Understand value functions, as a general-purpose tool for optimal decision-making
- Know how to implement dynamic programming as an efficient solution approach to an industrial control problem
This course teaches you the key concepts of Reinforcement Learning, underlying classic and modern algorithms in RL. After completing this course, you will be able to start using RL for real problems, where you have or can specify the MDP.
This is the first course of the Reinforcement Learning Specialization.
Transfer Learning for Food Classification
In this hands-on project, we will train a deep learning model to predict the type of food and then fine tune the model to improve its performance. This project could be practically applied in food industry to detect the type and quality of food. In this 2-hours long project-based course, you will be able to:
- Understand the theory and intuition behind Convolutional Neural Networks (CNNs).
- Understand the theory and intuition behind transfer learning.
- Import Key libraries, dataset and visualize images.
- Perform data augmentation.
- Build a Deep Learning Model using Pre-Trained InceptionResnetV2.
- Compile and fit Deep Learning model to training data.
- Assess the performance of trained CNN and ensure its generalization using various KPIs.
Data Visualization & Storytelling in Python
Hello everyone and welcome to this new hands-on project on data visualization and storytelling in python. In this project, we will leverage 3 powerful libraries known as Seaborn, Matplotlib and Plotly to visualize data in an interactive way. This project is practical and directly applicable to many industries. You can add this project to your portfolio of projects which is essential for your next job interview.
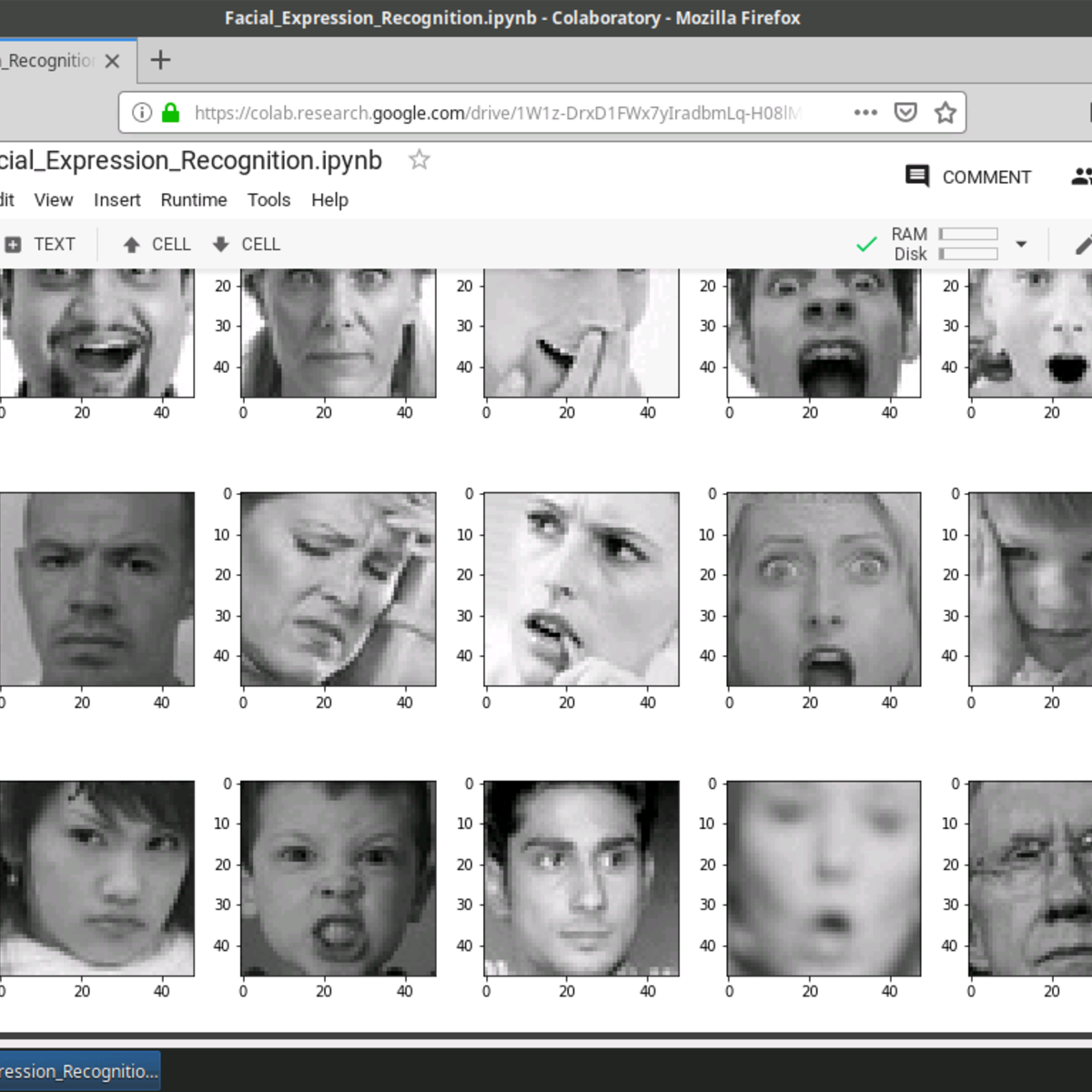
Facial Expression Recognition with Keras
In this 2-hour long project-based course, you will build and train a convolutional neural network (CNN) in Keras from scratch to recognize facial expressions. The data consists of 48x48 pixel grayscale images of faces. The objective is to classify each face based on the emotion shown in the facial expression into one of seven categories (0=Angry, 1=Disgust, 2=Fear, 3=Happy, 4=Sad, 5=Surprise, 6=Neutral). You will use OpenCV to automatically detect faces in images and draw bounding boxes around them. Once you have trained, saved, and exported the CNN, you will directly serve the trained model to a web interface and perform real-time facial expression recognition on video and image data.
This course runs on Coursera's hands-on project platform called Rhyme. On Rhyme, you do projects in a hands-on manner in your browser. You will get instant access to pre-configured cloud desktops containing all of the software and data you need for the project. Everything is already set up directly in your internet browser so you can just focus on learning. For this project, you’ll get instant access to a cloud desktop with Python, Jupyter, and Keras pre-installed.
Notes:
- You will be able to access the cloud desktop 5 times. However, you will be able to access instructions videos as many times as you want.
- This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Predict Housing Prices with Tensorflow and AI Platform
This is a self-paced lab that takes place in the Google Cloud console. In this lab you will build an end to end machine learning solution using Tensorflow + AI Platform and leverage the cloud for distributed training and online prediction.
Building Recommendation System Using MXNET on AWS Sagemaker
Please note: You will need an AWS account to complete this course. Your AWS account will be charged as per your usage. Please make sure that you are able to access Sagemaker within your AWS account. If your AWS account is new, you may need to ask AWS support for access to certain resources. You should be familiar with python programming, and AWS before starting this hands on project. We use a Sagemaker P type instance in this project for training the model, and if you don't have access to this instance type, please contact AWS support and request access.
In this 2-hour long project-based course, you will how to train and deploy a Recommendation System using AWS Sagemaker. We will go through the detailed step by step process of training a recommendation system on the Amazon's Electronics dataset. We will be using a Notebook Instance to build our training model. You will learn how to use Apache's MXNET Deep Learning Model on the AWS Sagemaker platform.
Since this is a practical, project-based course, we will not dive in the theory behind recommendation systems, but will focus purely on training and deploying a model with AWS Sagemaker. You will also need to have some experience with Amazon Web Services (AWS) and knowledge of how deep learning frameworks work.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Image Compression and Generation using Variational Autoencoders in Python
In this 1-hour long project, you will be introduced to the Variational Autoencoder. We will discuss some basic theory behind this model, and move on to creating a machine learning project based on this architecture. Our data comprises 60.000 characters from a dataset of fonts. We will train a variational autoencoder that will be capable of compressing this character font data from 2500 dimensions down to 32 dimensions. This same model will be able to then reconstruct its original input with high fidelity. The true advantage of the variational autoencoder is its ability to create new outputs that come from distributions that closely follow its training data: we can output characters in brand new fonts.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Popular Internships and Jobs by Categories
Browse
© 2024 BoostGrad | All rights reserved