Back to Courses







Data Analysis Courses - Page 3
Showing results 21-30 of 998
The Social and Technical Context of Health Informatics
Improving health and healthcare institutions requires understanding of data and creation of interventions at the many levels at which health IT interact and affect the institution. These levels range from the external “world” in which the institution operates down to the specific technologies. Data scientists find that, when they aim at implementing their models in practice, it is the “socio” components that are both novel to them and mission critical to success. At the end of this course, students will be able to make a quick assessment of a health informatics problem—or a proposed solution—and to determine what is missing and what more needs to be learned.
Who Is This Class For?
Physicians, nurses, pharmacists, social workers, and other allied health professionals interested in expanding their understanding of digital health, big data, health information systems, and the unintended consequences of disruptive innovation in the healthcare system. The course is also aimed at those with technical, engineering, or analytics backgrounds who want to understand the nuances of those topics when it comes to healthcare.
Materials Data Sciences and Informatics
This course aims to provide a succinct overview of the emerging discipline of Materials Informatics at the intersection of materials science, computational science, and information science. Attention is drawn to specific opportunities afforded by this new field in accelerating materials development and deployment efforts. A particular emphasis is placed on materials exhibiting hierarchical internal structures spanning multiple length/structure scales and the impediments involved in establishing invertible process-structure-property (PSP) linkages for these materials. More specifically, it is argued that modern data sciences (including advanced statistics, dimensionality reduction, and formulation of metamodels) and innovative cyberinfrastructure tools (including integration platforms, databases, and customized tools for enhancement of collaborations among cross-disciplinary team members) are likely to play a critical and pivotal role in addressing the above challenges.
Analyze Survey Data with Tableau
Surveys are used in a variety of scenarios, both in businesses and in research. Companies are using them to better understand consumer insights and feedback, and researchers are going beyond the traditional uses to learn more about the world around us. Tableau can help visualize survey data of all kinds in a useful way—without needing advanced statistics, graphic design, or a statistics background.
In this project, learners will learn how to create an account in Tableau and how to manipulate data with joins and pivots. Students will then learn how to create different kinds of visualizations, including tables, pie charts, and a stacked pie chart.
This would be a great project for business and academic uses of survey data.
This project is designed to be used by those somewhat familiar with Tableau and data visualizations. But the project can be accessible for those new to Tableau as well.
Essential Design Principles for Tableau
In this course, you will analyze and apply essential design principles to your Tableau visualizations. This course assumes you understand the tools within Tableau and have some knowledge of the fundamental concepts of data visualization. You will define and examine the similarities and differences of exploratory and explanatory analysis as well as begin to ask the right questions about what’s needed in a visualization. You will assess how data and design work together, including how to choose the appropriate visual representation for your data, and the difference between effective and ineffective visuals. You will apply effective best practice design principles to your data visualizations and be able to illustrate examples of strategic use of contrast to highlight important elements. You will evaluate pre-attentive attributes and why they are important in visualizations. You will exam the importance of using the "right" amount of color and in the right place and be able to apply design principles to de-clutter your data visualization.
Fundamentals of Scalable Data Science
Apache Spark is the de-facto standard for large scale data processing. This is the first course of a series of courses towards the IBM Advanced Data Science Specialization. We strongly believe that is is crucial for success to start learning a scalable data science platform since memory and CPU constraints are to most limiting factors when it comes to building advanced machine learning models.
In this course we teach you the fundamentals of Apache Spark using python and pyspark. We'll introduce Apache Spark in the first two weeks and learn how to apply it to compute basic exploratory and data pre-processing tasks in the last two weeks. Through this exercise you'll also be introduced to the most fundamental statistical measures and data visualization technologies.
This gives you enough knowledge to take over the role of a data engineer in any modern environment. But it gives you also the basis for advancing your career towards data science.
Please have a look at the full specialization curriculum:
https://www.coursera.org/specializations/advanced-data-science-ibm
If you choose to take this course and earn the Coursera course certificate, you will also earn an IBM digital badge. To find out more about IBM digital badges follow the link ibm.biz/badging.
After completing this course, you will be able to:
• Describe how basic statistical measures, are used to reveal patterns within the data
• Recognize data characteristics, patterns, trends, deviations or inconsistencies, and potential outliers.
• Identify useful techniques for working with big data such as dimension reduction and feature selection methods
• Use advanced tools and charting libraries to:
o improve efficiency of analysis of big-data with partitioning and parallel analysis
o Visualize the data in an number of 2D and 3D formats (Box Plot, Run Chart, Scatter Plot, Pareto Chart, and Multidimensional Scaling)
For successful completion of the course, the following prerequisites are recommended:
• Basic programming skills in python
• Basic math
• Basic SQL (you can get it easily from https://www.coursera.org/learn/sql-data-science if needed)
In order to complete this course, the following technologies will be used:
(These technologies are introduced in the course as necessary so no previous knowledge is required.)
• Jupyter notebooks (brought to you by IBM Watson Studio for free)
• ApacheSpark (brought to you by IBM Watson Studio for free)
• Python
We've been reported that some of the material in this course is too advanced. So in case you feel the same, please have a look at the following materials first before starting this course, we've been reported that this really helps.
Of course, you can give this course a try first and then in case you need, take the following courses / materials. It's free...
https://cognitiveclass.ai/learn/spark
https://dataplatform.cloud.ibm.com/analytics/notebooks/v2/f8982db1-5e55-46d6-a272-fd11b670be38/view?access_token=533a1925cd1c4c362aabe7b3336b3eae2a99e0dc923ec0775d891c31c5bbbc68
This course takes four weeks, 4-6h per week
Stability and Capability in Quality Improvement
In this course, you will learn to analyze data in terms of process stability and statistical control and why having a stable process is imperative prior to perform statistical hypothesis testing. You will create statistical process control charts for both continuous and discrete data using R software. You will analyze data sets for statistical control using control rules based on probability. Additionally, you will learn how to assess a process with respect to how capable it is of meeting specifications, either internal or external, and make decisions about process improvement.
This course can be taken for academic credit as part of CU Boulder’s Master of Science in Data Science (MS-DS) degree offered on the Coursera platform. The MS-DS is an interdisciplinary degree that brings together faculty from CU Boulder’s departments of Applied Mathematics, Computer Science, Information Science, and others. With performance-based admissions and no application process, the MS-DS is ideal for individuals with a broad range of undergraduate education and/or professional experience in computer science, information science, mathematics, and statistics. Learn more about the MS-DS program at https://www.coursera.org/degrees/master-of-science-data-science-boulder.
Generalized Linear Models and Nonparametric Regression
In the final course of the statistical modeling for data science program, learners will study a broad set of more advanced statistical modeling tools. Such tools will include generalized linear models (GLMs), which will provide an introduction to classification (through logistic regression); nonparametric modeling, including kernel estimators, smoothing splines; and semi-parametric generalized additive models (GAMs). Emphasis will be placed on a firm conceptual understanding of these tools. Attention will also be given to ethical issues raised by using complicated statistical models.
This course can be taken for academic credit as part of CU Boulder’s Master of Science in Data Science (MS-DS) degree offered on the Coursera platform. The MS-DS is an interdisciplinary degree that brings together faculty from CU Boulder’s departments of Applied Mathematics, Computer Science, Information Science, and others. With performance-based admissions and no application process, the MS-DS is ideal for individuals with a broad range of undergraduate education and/or professional experience in computer science, information science, mathematics, and statistics. Learn more about the MS-DS program at https://www.coursera.org/degrees/master-of-science-data-science-boulder.
Logo adapted from photo by Vincent Ledvina on Unsplash
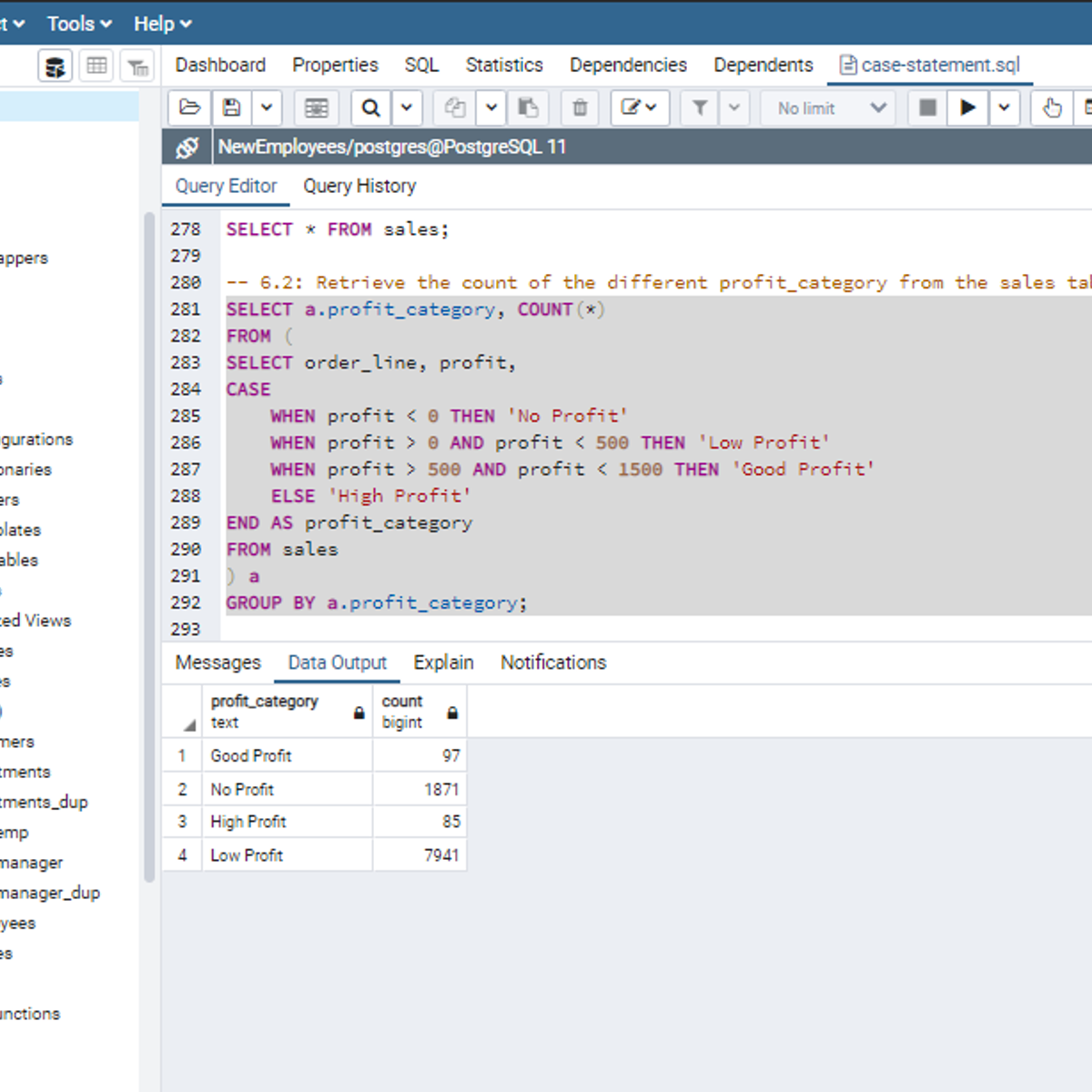
SQL CASE Statements
Welcome to this project-based course, SQL CASE Statements. In this project, you will learn how to use SQL CASE statements to query tables in a database.
By the end of this 2-hour long project, you will be able to write simple CASE statements to retrieve the desired result from a database. Then, we will move systematically to write more complex SQL CASE statements. Furthermore, we will see how to use the CASE clause together with aggregate functions, and SQL joins to get the desired result you want from tables in a database. Also, you will learn how to use the CASE clause to transpose the result of a query.
Also, for this hands-on project, we will use PostgreSQL as our preferred database management system (DBMS). Therefore, to complete this project, it is required that you have prior experience with using PostgreSQL. Similarly, this project is an advanced SQL concept; so, a good foundation for writing SQL queries, and performing joins in SQL is vital to complete this project.
If you are not familiar with writing queries in SQL and SQL joins and want to learn these concepts, start with my previous guided projects titled “Querying Databases using SQL SELECT statement", “Performing Data Aggregation using SQL Aggregate Functions” and “Mastering SQL Joins”. I taught these guided projects using PostgreSQL. So, taking these projects will give the needed requisite to complete this project on SQL CASE Statements. However, if you are comfortable writing queries in PostgreSQL, please join me on this wonderful ride! Let’s get our hands dirty!
Developing Data Models with LookML
This course empowers you to develop scalable, performant LookML (Looker Modeling Language) models that provide your business users with the standardized, ready-to-use data that they need to answer their questions. Upon completing this course, you will be able to start building and maintaining LookML models to curate and manage data in your organization’s Looker instance.
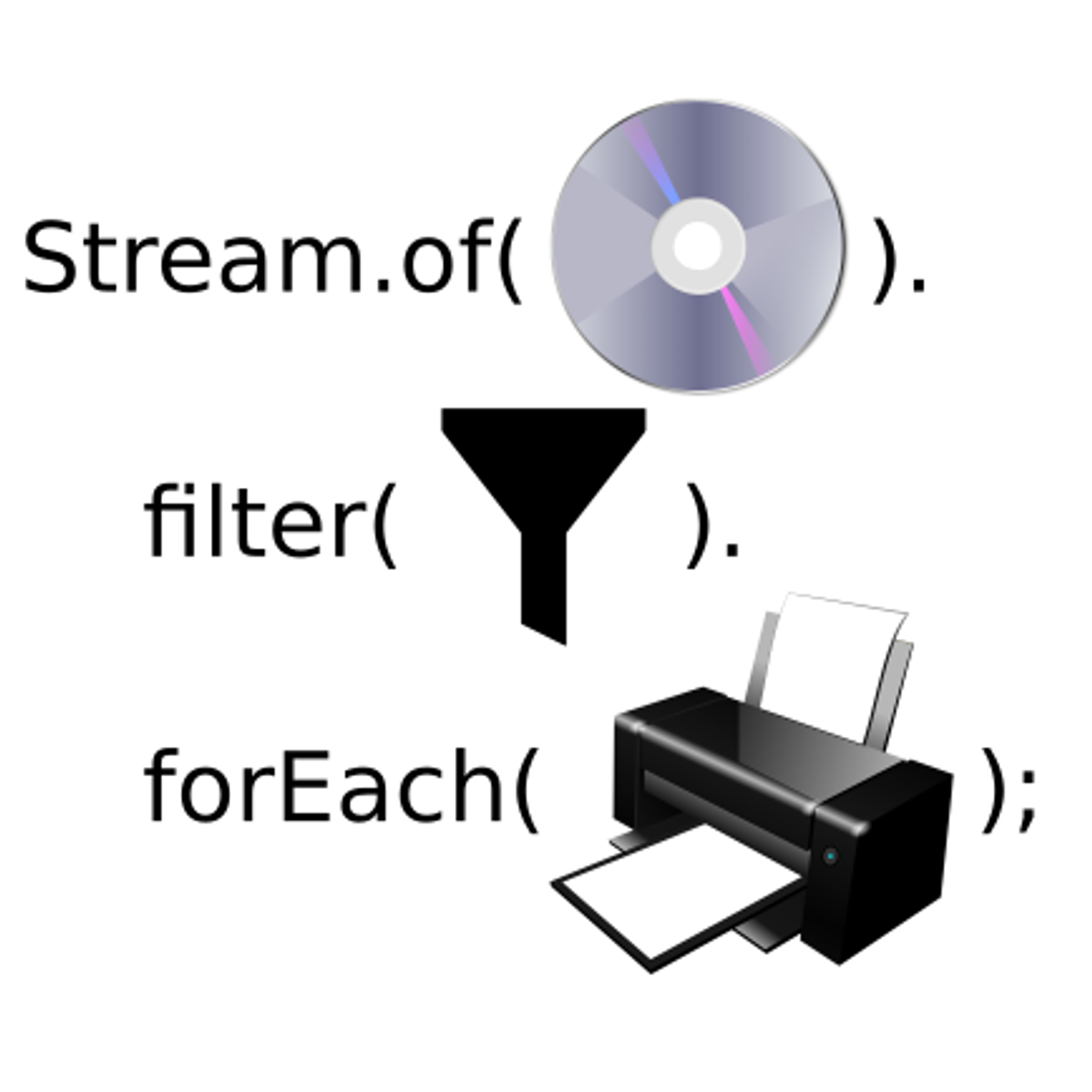
Perform basic data analysis tasks using Java streams
In this 1-hour long project-based course, you will learn how to create a Java Stream object based on an array of data, and understand the distinction between terminal and intermediate stream operations. You will iterate through the data stream using the forEach method, and use a range of Stream methods to perform logical operations on the data stream. You will perform basic statistical calculations on a stream of numeric data, and string operations on a stream of string data. You will learn how to use the map, filter, and reduce Stream methods. Finally, you will learn how to load a CSV file, the COVID vaccination dataset, and turn it into a data stream, and perform basic exploratory analysis of the data.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Popular Internships and Jobs by Categories
Find Jobs & Internships
Browse





© 2024 BoostGrad | All rights reserved