
Back to Courses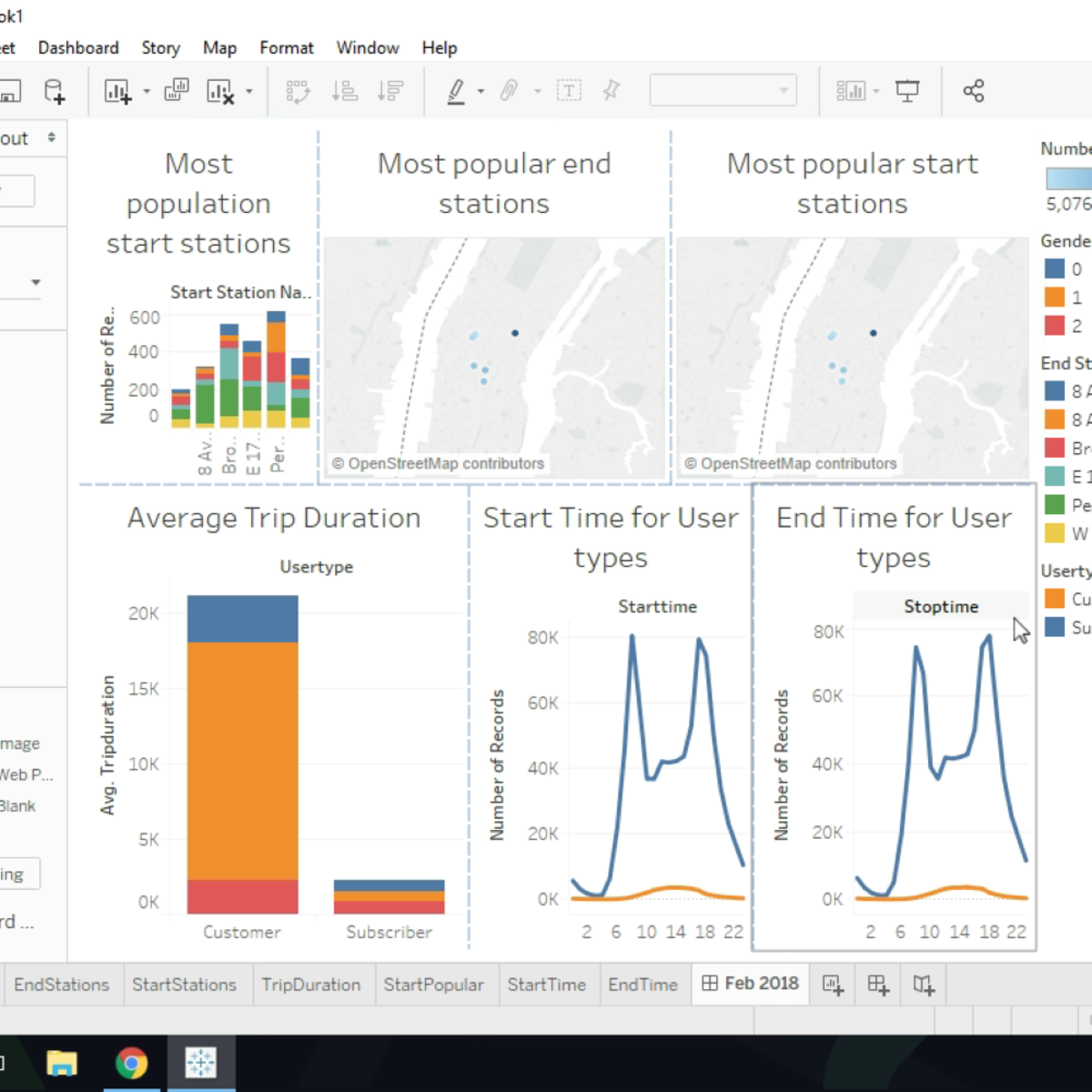








Data Science Courses - Page 43
Showing results 421-430 of 1407
Visualizing Citibike Trips with Tableau
In this 1-hour long project-based course, you will learn the basics of using Tableau Public software to visualize Citibike Trips Dataset. By the end of this project, you will have created a few visualizations and a collection of visualizations called a dashboard.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Statistics for Machine Learning for Investment Professionals
One of the biggest changes in the past decade is the rapid adoption of machine learning, AI, and big data in investment decision making. This course introduces learners with knowledge of the investment industry to foundational statistical concepts underpinning machine learning as well as advanced AI techniques. This course demonstrates core modeling frameworks along with carefully selected real-world investment practice examples. The course seeks to familiarize learners with two important programming languages — Python and R (no prior knowledge of Python or R necessary). The motivation is to demonstrate the elegance — and speed — simple programming brings to the investment decision-making process. The reading material in this course offers in-practice insights curated from the blogs of CFA Institute as well as other leading publications.
After taking this course you will be able to:
- Describe the importance of identifying information patterns for building models
- Explain probability concepts for solving investing problems
- Explain the use of linear regression and interpret related Python and R code
- Describe gradient descent, explain logistic regression, and interpret Python and R code
- Describe the characteristics and uses of time-series models
This course is part of the Data Science for Investment Professionals Specialization offered by CFA Institute.
Migrating an application and data from Apache Cassandra™ to DataStax Enterprise
This is a self-paced lab that takes place in the Google Cloud console. In this lab, you will learn how to migrate an application running on Apache Cassandra™ to DataStax Enterprise (DSE). To do this, you will deploy a Cassandra™ database and an application that writes data into it. You will then deploy a DataStax Enterprise database and connect the same application to the database. Finally, you will learn how to migrate data from Apache Cassandra™ to DSE using the The DataStax Bulk Loader dsbulk.
Deploy a predictive machine learning model using IBM Cloud
In this 1-hour long project-based course, you will be able to create, evaluate and save a machine learning model (without writing a single line of code) using Watson Studio on IBM Cloud Platform, and you will make deployment of the model and try out as a web service frontend to make predictions.
This guided project is for Data Scientists, Machine Learning Engineers, and Developers who want a way to deliver their machine learning code available to be integrated into an application and using it as a web service. We will do everything in a development mode without any costs using a free IBM Cloud account.
To be successful in this project, you should be familiar with machine learning methodologies, like training, prediction, evaluation, and basic knowledge in some machine learning algorithms is appreciated too, so that way you will understand the results before making a deployment.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Capstone Assignment - CDSS 5
This course is a capstone assignment requiring you to apply the knowledge and skill you have learnt throughout the specialization. In this course you will choose one of the areas and complete the assignment to pass.
Linear Regression in R for Public Health
Welcome to Linear Regression in R for Public Health!
Public Health has been defined as “the art and science of preventing disease, prolonging life and promoting health through the organized efforts of society”. Knowing what causes disease and what makes it worse are clearly vital parts of this. This requires the development of statistical models that describe how patient and environmental factors affect our chances of getting ill. This course will show you how to create such models from scratch, beginning with introducing you to the concept of correlation and linear regression before walking you through importing and examining your data, and then showing you how to fit models. Using the example of respiratory disease, these models will describe how patient and other factors affect outcomes such as lung function.
Linear regression is one of a family of regression models, and the other courses in this series will cover two further members. Regression models have many things in common with each other, though the mathematical details differ.
This course will show you how to prepare the data, assess how well the model fits the data, and test its underlying assumptions – vital tasks with any type of regression.
You will use the free and versatile software package R, used by statisticians and data scientists in academia, governments and industry worldwide.
Healthcare Data Literacy
This course will help lay the foundation of your healthcare data journey and provide you with knowledge and skills necessary to work in the healthcare industry as a data scientist. Healthcare is unique because it is associated with continually evolving and complex processes associated with health management and medical care. We'll learn about the many facets to consider in healthcare and determine the value and growing need for data analysts in healthcare. We'll learn about the Triple Aim and other data-enabled healthcare drivers. We'll cover different concepts and categories of healthcare data and describe how ontologies and related terms such as taxonomy and terminology organize concepts and facilitate computation. We'll discuss the common clinical representations of data in healthcare systems, including ICD-10, SNOMED, LOINC, drug vocabularies (e.g., RxNorm), and clinical data standards. We’ll discuss the various types of healthcare data and assess the complexity that occurs as you work with pulling in all the different types of data to aid in decisions. We will analyze various types and sources of healthcare data, including clinical, operational claims, and patient generated data as well as differentiate unstructured, semi-structured and structured data within health data contexts. We'll examine the inner workings of data and conceptual harmony offer some solutions to the data integration problem by defining some important concepts, methods, and applications that are important to this domain.
Data Analytics in Accounting Capstone
This capstone is the last course in the Data Analytics in Accountancy Specialization. In this capstone course, you are going to take the knowledge and skills you have acquired from the previous courses and apply them to a real-world problem.
You will be provided with a loan dataset from Lending Club which is the largest peer-to-peer lending platform. You will explore the characteristics of the features in the dataset through statistical analysis, exploratory data analysis and visualization. You will also create a machine learning model to predict whether a loan will be fully paid or not. Finally, you will construct a portfolio with the help of your analysis. The goal is to create a portfolio that achieves better return than the overall return of all loans on the Lending Club platform.
Collect Metrics from Exporters using the Managed Service for Prometheus
This is a self-paced lab that takes place in the Google Cloud console. In this lab, you will explore using the Managed Service for Prometheus to collect metrics from other infrastructure sources via exporters.
Machine Learning Rapid Prototyping with IBM Watson Studio
An emerging trend in AI is the availability of technologies in which automation is used to select a best-fit model, perform feature engineering and improve model performance via hyperparameter optimization. This automation will provide rapid-prototyping of models and allow the Data Scientist to focus their efforts on applying domain knowledge to fine-tune models. This course will take the learner through the creation of an end-to-end automated pipeline built by Watson Studio’s AutoAI experiment tool, explaining the underlying technology at work as developed by IBM Research. The focus will be on working with an auto-generated Python notebook. Learners will be provided with test data sets for two use cases.
This course is intended for practicing Data Scientists. While it showcases the automated AI capabilies of IBM Watson Studio with AutoAI, the course does not explain Machine Learning or Data Science concepts.
In order to be successful, you should have knowledge of:
Data Science workflow
Data Preprocessing
Feature Engineering
Machine Learning Algorithms
Hyperparameter Optimization
Evaluation measures for models
Python and scikit-learn library (including Pipeline class)
Popular Internships and Jobs by Categories
Browse
© 2024 BoostGrad | All rights reserved