
Back to Courses






Data Science Courses - Page 129
Showing results 1281-1290 of 1407
Exploring and Analyzing Fifa's Datasets Using Python
In this 1-hour long project-based course, you will learn how to load a dataset into a pandas dataframe, you will learn how to tidy a messy dataset (Data Tidying), you will get to also visualize the dataset using Matplotlib and seaborn, you will learn how to engineer new features, you will also get to learn how to merge datasets (Data Integration)
By the end of this project, you will be able to fully analyze a FIFA dataset using python’s Pandas library. Throughout the tasks you will be able to identify and apply the key aspects about data analysis such as Data Cleaning, Data transformation, Data Visualization , Data tidying and feature engineering.
All these skills are crucial to the world of data engineering and are very beneficial in today’s job market that is leaning more and more towards utilizing data in every way
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Regression Modeling in Practice
This course focuses on one of the most important tools in your data analysis arsenal: regression analysis. Using either SAS or Python, you will begin with linear regression and then learn how to adapt when two variables do not present a clear linear relationship. You will examine multiple predictors of your outcome and be able to identify confounding variables, which can tell a more compelling story about your results. You will learn the assumptions underlying regression analysis, how to interpret regression coefficients, and how to use regression diagnostic plots and other tools to evaluate the quality of your regression model. Throughout the course, you will share with others the regression models you have developed and the stories they tell you.
Machine Learning Models in Science
This course is aimed at anyone interested in applying machine learning techniques to scientific problems. In this course, we'll learn about the complete machine learning pipeline, from reading in, cleaning, and transforming data to running basic and advanced machine learning algorithms. We'll start with data preprocessing techniques, such as PCA and LDA. Then, we'll dive into the fundamental AI algorithms: SVMs and K-means clustering. Along the way, we'll build our mathematical and programming toolbox to prepare ourselves to work with more complicated models. Finally, we'll explored advanced methods such as random forests and neural networks. Throughout the way, we'll be using medical and astronomical datasets. In the final project, we'll apply our skills to compare different machine learning models in Python.
Calculus through Data & Modeling: Limits & Derivatives
This first course on concepts of single variable calculus will introduce the notions of limits of a function to define the derivative of a function. In mathematics, the derivative measures the sensitivity to change of the function. For example, the derivative of the position of a moving object with respect to time is the object's velocity: this measures how quickly the position of the object changes when time advances. This fundamental notion will be applied through the modelling and analysis of data.
Prisma Cloud: Protect your Cloud Instance with Host Defender
This is a self-paced lab that takes place in the Google Cloud console.
Host Defender is deployed to each Compute Engine instance to secure the cloud workload. The Host Defender protects your environment according to the security policies configured in the Prisma Cloud Console.
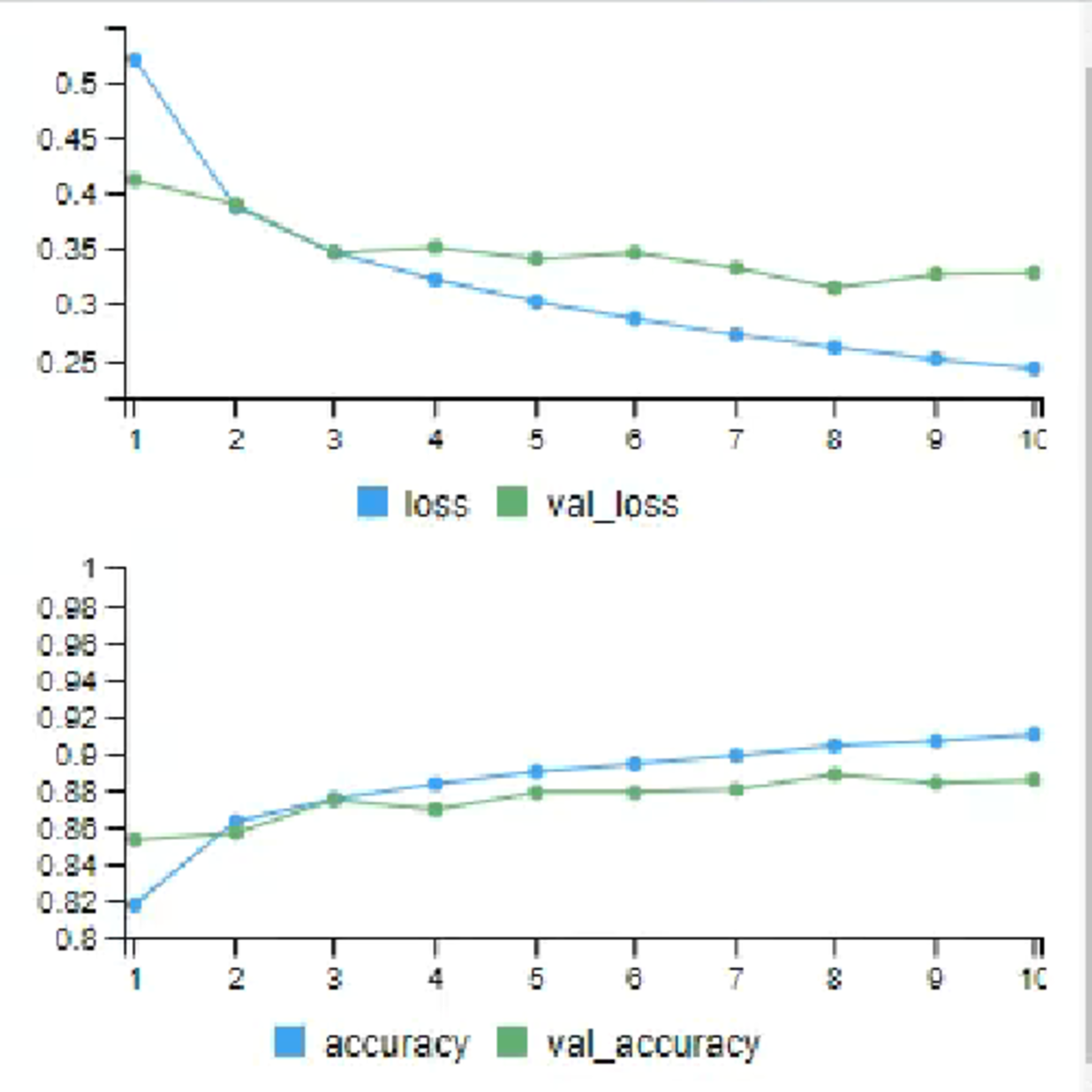
Build a Deep Learning Based Image Classifier with R
In this 45-min guided project, you will learn the basics of using the Keras interface to R with Tensorflow as its backend to solve an image classification problem. By the time you complete this project, you will have used the R programming language to build, train, and evaluate a neural network model to classify images of clothing items into categories such as t-shirts, trousers, and sneakers. We will be training the deep learning based image classification model on the Fashion MNIST dataset which contains 70000 grayscale images of clothes across 10 categories.
In order to be successful in this project, you should be familiar with R programming, and basics of neural networks.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
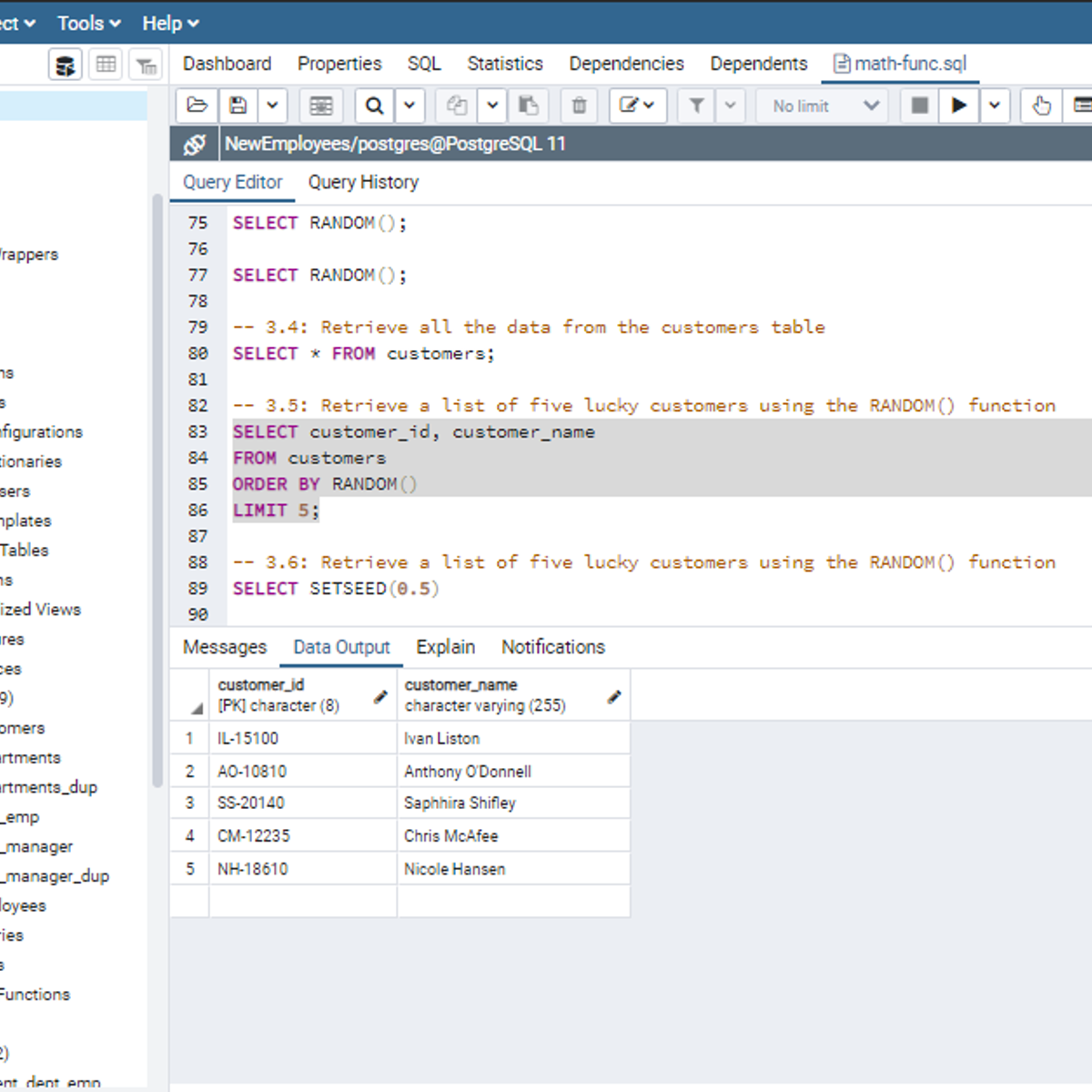
SQL Mathematical Functions
Welcome to this project-based course, SQL Mathematical Functions. In this project, you will learn how to use SQL Mathematical Functions to manipulate tables in a database.
By the end of this 2-hour-long project, you will be able to use different Mathematical Functions to retrieve the desired result from a database. In this project, you will learn how to use SQL Mathematical Functions like CEIL(), FLOOR(), RANDOM(), SETSEED(), ROUND(), TRUNC(), SQRT(), CBRT(), and POWER() to manipulate data in the employees database. In this project, we will move systematically by first introducing the functions using a simple example. Then, we will write slightly complex queries using the Mathematical Functions in real-life applications.
Also, for this hands-on project, we will use PostgreSQL as our preferred database management system (DBMS). Therefore, to complete this project, it is required that you have prior experience with using PostgreSQL. Similarly, this project is an intermediate SQL concept; so, a good foundation for writing SQL queries is vital to complete this project.
If you are not familiar with writing queries in SQL and want to learn these concepts, start with my previous guided projects titled “Querying Databases using SQL SELECT statement," and “Performing Data Aggregation using SQL Aggregate Functions.” I taught these guided projects using PostgreSQL. So, taking these projects will give the needed requisite to complete this SQL Mathematical Functions project. However, if you are comfortable writing queries in PostgreSQL, please join me on this wonderful ride! Let’s get our hands dirty!
Bayesian Statistics: Capstone Project
This is the capstone project for UC Santa Cruz's Bayesian Statistics Specialization. It is an opportunity for you to demonstrate a wide range of skills and knowledge in Bayesian statistics and to apply what you know to real-world data. You will review essential concepts in Bayesian statistics with lecture videos and quizzes, and you will perform a complex data analysis and compose a report on your methods and results.
JSON and Natural Language Processing in PostgreSQL
Within this course, you’ll learn about how PostgreSQL creates and uses inverted indexes for JSON and natural language content. We will use various sources of data for our databases, including access to an online API and spidering its data and storing the data in a JSON column in PostgreSQL. Students will explore how full-text inverted indexes are structured. Students will build their own inverted indexes and then make use of PostgreSQL built-in capabilities to support full-text indexes.
The Structured Query Language (SQL)
In this course you will learn all about the Structured Query Language ("SQL".) We will review the origins of the language and its conceptual foundations. But primarily, we will focus on learning all the standard SQL commands, their syntax, and how to use these commands to conduct analysis of the data within a relational database. Our scope includes not only the SELECT statement for retrieving data and creating analytical reports, but also includes the DDL ("Data Definition Language") and DML ("Data Manipulation Language") commands necessary to create and maintain database objects.
The Structured Query Language (SQL) can be taken for academic credit as part of CU Boulder’s Master of Science in Data Science (MS-DS) degree offered on the Coursera platform. The MS-DS is an interdisciplinary degree that brings together faculty from CU Boulder’s departments of Applied Mathematics, Computer Science, Information Science, and others. With performance-based admissions and no application process, the MS-DS is ideal for individuals with a broad range of undergraduate education and/or professional experience in computer science, information science, mathematics, and statistics. Learn more about the MS-DS program at https://www.coursera.org/degrees/master-of-science-data-science-boulder.