Back to Courses






Machine Learning Courses - Page 37
Showing results 361-370 of 485
Image Noise Reduction with Auto-encoders using TensorFlow
In this 2-hour long project-based course, you will learn the basics of image noise reduction with auto-encoders. Auto-encoding is an algorithm to help reduce dimensionality of data with the help of neural networks. It can be used for lossy data compression where the compression is dependent on the given data. This algorithm to reduce dimensionality of data as learned from the data can also be used for reducing noise in data.
This course runs on Coursera's hands-on project platform called Rhyme. On Rhyme, you do projects in a hands-on manner in your browser. You will get instant access to pre-configured cloud desktops containing all of the software and data you need for the project. Everything is already set up directly in your internet browser so you can just focus on learning. For this project, you’ll get instant access to a cloud desktop with Python, Jupyter, and Tensorflow pre-installed.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Text Retrieval and Search Engines
Recent years have seen a dramatic growth of natural language text data, including web pages, news articles, scientific literature, emails, enterprise documents, and social media such as blog articles, forum posts, product reviews, and tweets. Text data are unique in that they are usually generated directly by humans rather than a computer system or sensors, and are thus especially valuable for discovering knowledge about people’s opinions and preferences, in addition to many other kinds of knowledge that we encode in text.
This course will cover search engine technologies, which play an important role in any data mining applications involving text data for two reasons. First, while the raw data may be large for any particular problem, it is often a relatively small subset of the data that are relevant, and a search engine is an essential tool for quickly discovering a small subset of relevant text data in a large text collection. Second, search engines are needed to help analysts interpret any patterns discovered in the data by allowing them to examine the relevant original text data to make sense of any discovered pattern. You will learn the basic concepts, principles, and the major techniques in text retrieval, which is the underlying science of search engines.
Creating a Wordcloud using NLP and TF-IDF in Python
By the end of this project, you will learn how to create a professional looking wordcloud from a text dataset in Python. You will use an open source dataset containing Christmas recipes and will create a wordcloud of the most important ingredients used in these recipes. I will teach you how load a JSON dataset, clean the dataset by removing encodings and unwanted characters, and lemmatize your dataset. I will also teach you how to calculate TF-IDF weights of words in your dataset and use these weights to create a wordcloud. You will create a ready-to-use Jupyter notebook for creating a wordcloud on any text dataset.
Lemmatization is a process of removing inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma. TF-IDF stands for term frequency-inverse document frequency. TF-IDF gives a weight to each word which tells how important that term is. Using both lemmatization and TF-IDF, one can find the important words in the text dataset and use these important words to create the wordcloud. For example, these datasets could be customer complaints and the business can focus on the important issues that the customers are facing. Wordcloud is a powerful resource which can be used in reports and presentations.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Build your first Machine Learning Pipeline using Dataiku
As part of this guided project, you shall build your first Machine Learning Pipeline using DataIku tool without writing a single line of code. You shall build a prediction model which inputs COVID daily count data across the world and predict COVID fatalities.DataIku tool is a low code no code platform which is gaining traction with citizen data scientist to quickly build and deploy their models.
Compare Models with Experiments in Azure ML Studio
Did you know that you can compare models in Azure Machine Learning?
In this 1-hour project-based course, you will learn how to log plots in experiments, log numeric metrics in experiments and visualize metrics in Azure Machine Learning Studio. To achieve this, we will use one example data, train a couple of machine learning algorithms in Jupyter notebook and visualize their results in Azure Machine Learning Studio Portal interface.
In order to be successful in this project, you will need knowledge of Python language and experience with machine learning in Python. Also, Azure subscription is required (free trial is an option for those who don’t have it), as well as Azure Machine Learning resource and a compute instance within. Instructional links will be provided to guide you through creation, if needed, in the first task.
If you are ready to make your experience training models simpler and more enjoyable, this is a course for you!
Let’s get started!
CUDA Advanced Libraries
This course will complete the GPU specialization, focusing on the leading libraries distributed as part of the CUDA Toolkit. Students will learn how to use CuFFT, and linear algebra libraries to perform complex mathematical computations. The Thrust library’s capabilities in representing common data structures and associated algorithms will be introduced. Using cuDNN and cuTensor they will be able to develop machine learning applications that help with object detection, human language translation and image classification.
Health Data Science Foundation
This course is intended for persons involved in machine learning who are interested in medical applications, or vice versa, medical professionals who are interested in the methods modern computer science has to offer to their field. We will cover health data analysis, different types of neural networks, as well as training and application of neural networks applied on real-world medical scenarios.
We cover deep learning (DL) methods, healthcare data and applications using DL methods. The courses include activities such as video lectures, self guided programming labs, homework assignments (both written and programming), and a large project.
The first phase of the course will include video lectures on different DL and health applications topics, self-guided labs and multiple homework assignments. In this phase, you will build up your knowledge and experience in developing practical deep learning models on healthcare data. The second phase of the course will be a large project that can lead to a technical report and functioning demo of the deep learning models for addressing some specific healthcare problems. We expect the best projects can potentially lead to scientific publications.
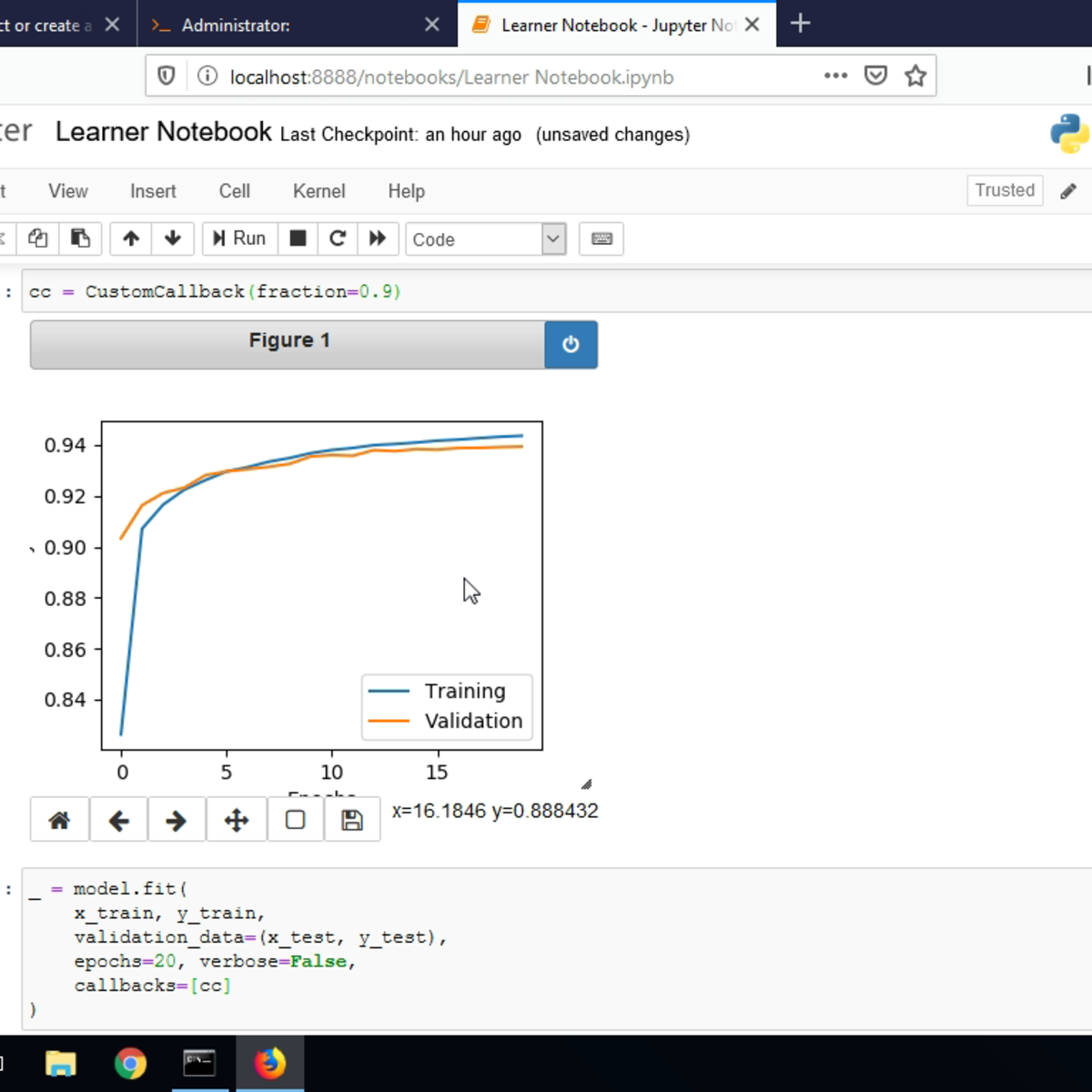
Creating Custom Callbacks in Keras
In this 1.5-hour long project-based course, you will learn to create a custom callback function in Keras and use the callback during a model training process. We will implement the callback function to perform three tasks: Write a log file during the training process, plot the training metrics in a graph during the training process, and reduce the learning rate during the training with each epoch.
This course runs on Coursera's hands-on project platform called Rhyme. On Rhyme, you do projects in a hands-on manner in your browser. You will get instant access to pre-configured cloud desktops containing all of the software and data you need for the project. Everything is already set up directly in your Internet browser so you can just focus on learning. For this project, you’ll get instant access to a cloud desktop with (e.g. Python, Jupyter, and Tensorflow) pre-installed.
Prerequisites:
In order to be successful in this project, you should be familiar with Python, Neural Networks, and the Keras framework.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Detect Fake News in Python with Tensorflow
"Fake News" is a word used to mean different things to different people. At its heart, we define "fake news" as any news stories which are false: the article itself is fabricated without verifiable evidence, citations or quotations. Often these stories may be lies and propaganda that is deliberately intended to confuse the viewer, or may be characterized as "click-bait" written for monetary incentives (the writer profits on the number of people who click on the story). In recent years, fake news stories have proliferated via social media, partially because they are so readily and widely spread online. Worse yet, Artificial Intelligence and natural language processing, or NLP, technology is ushering in an era of artificially-generated fake news. Both types of fake news are detectable with the use of NLP and deep learning.
In this project, you will learn multiple computational methods of identifying and classifying Fake News.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Evaluate Machine Learning Models with Yellowbrick
Welcome to this project-based course on Evaluating Machine Learning Models with Yellowbrick. In this course, we are going to use visualizations to steer our machine learning workflow. The problem we will tackle is to predict whether rooms in apartments are occupied or unoccupied based on passive sensor data such as temperature, humidity, light and CO2 levels. We will build a logistic regression model for binary classification. This is a continuation of the course on Room Occupancy Detection. With an emphasis on visual steering of our analysis, we will cover the following topics in our machine learning workflow: model evaluation with ROC/AUC plots, confusion matrices, cross-validation scores, and setting discrimination thresholds for logistic regression models.
This course runs on Coursera's hands-on project platform called Rhyme. On Rhyme, you do projects in a hands-on manner in your browser. You will get instant access to pre-configured cloud desktops containing all of the software and data you need for the project. Everything is already set up directly in your internet browser so you can just focus on learning. For this project, you’ll get instant access to a cloud desktop with Python, Jupyter, Yellowbrick, and scikit-learn pre-installed.
Notes:
- You will be able to access the cloud desktop 5 times. However, you will be able to access instructions videos as many times as you want.
- This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Popular Internships and Jobs by Categories
Find Jobs & Internships
Browse





© 2024 BoostGrad | All rights reserved