Back to Courses





Machine Learning Courses - Page 36
Showing results 351-360 of 485
Diabetes Disease Detection with XG-Boost and Neural Networks
In this project-based course, we will build, train and test a machine learning model to detect diabetes with XG-boost and Artificial Neural Networks. The objective of this project is to predict whether a patient has diabetes or not based on their given features and diagnostic measurements such as number of pregnancies, insulin levels, Body mass index, age and blood pressure.
Machine Learning With Big Data
Want to make sense of the volumes of data you have collected? Need to incorporate data-driven decisions into your process? This course provides an overview of machine learning techniques to explore, analyze, and leverage data. You will be introduced to tools and algorithms you can use to create machine learning models that learn from data, and to scale those models up to big data problems.
At the end of the course, you will be able to:
• Design an approach to leverage data using the steps in the machine learning process.
• Apply machine learning techniques to explore and prepare data for modeling.
• Identify the type of machine learning problem in order to apply the appropriate set of techniques.
• Construct models that learn from data using widely available open source tools.
• Analyze big data problems using scalable machine learning algorithms on Spark.
Software Requirements:
Cloudera VM, KNIME, Spark
Semantic Segmentation with Amazon Sagemaker
Please note: You will need an AWS account to complete this course. Your AWS account will be charged as per your usage. Please make sure that you are able to access Sagemaker within your AWS account. If your AWS account is new, you may need to ask AWS support for access to certain resources. You should be familiar with python programming, and AWS before starting this hands on project. We use a Sagemaker P type instance in this project, and if you don't have access to this instance type, please contact AWS support and request access.
In this 2-hour long project-based course, you will learn how to train and deploy a Semantic Segmentation model using Amazon Sagemaker. Sagemaker provides a number of machine learning algorithms ready to be used for solving a number of tasks. We will use the semantic segmentation algorithm from Sagemaker to create, train and deploy a model that will be able to segment images of dogs and cats from the popular IIIT-Oxford Pets Dataset into 3 unique pixel values. That is, each pixel of an input image would be classified as either foreground (pet), background (not a pet), or unclassified (transition between foreground and background).
Since this is a practical, project-based course, we will not dive in the theory behind deep learning based semantic segmentation, but will focus purely on training and deploying a model with Sagemaker. You will also need to have some experience with Amazon Web Services (AWS).
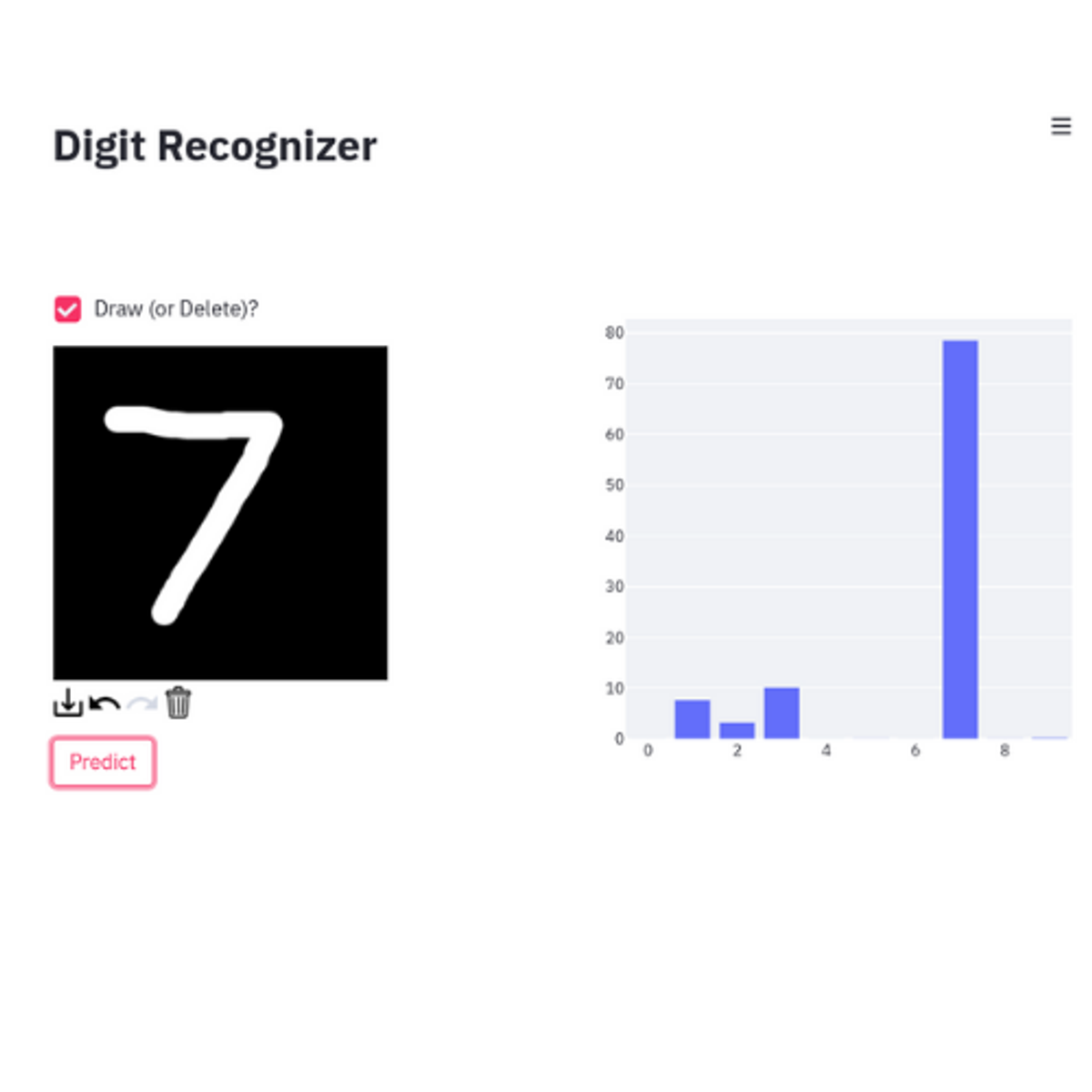
Create digit recognition web app with Streamlit
In this 1-hour long project-based course, you will learn how to create a digit recognition web application using streamlit. This project is divided into two stages. In the first stage, you are going to write the training pipeline in which you will load MNIST Handwritten dataset. You will write the training and validation functions in order to train and validate the dataset. Lastly, in this stage you will do inference. In the second stage, you will use the best trained model from the training pipeline and you will use that in your web app. You will create the web user interface using streamlit python library. In this web app a user will draw a digit and given that drawn digit, the best trained model will output the probabilities.
Understanding Deepfakes with Keras
In this 2-hour long project-based course, you will learn to implement DCGAN or Deep Convolutional Generative Adversarial Network, and you will train the network to generate realistic looking synthesized images. The term Deepfake is typically associated with synthetic data generated by Neural Networks which is similar to real-world, observed data - often with synthesized images, videos or audio. Through this hands-on project, we will go through the details of how such a network is structured, trained, and will ultimately generate synthetic images similar to hand-written digit 0 from the MNIST dataset.
Since this is a practical, project-based course, you will need to have a theoretical understanding of Neural Networks, Convolutional Neural Networks, and optimization algorithms like Gradient Descent. We will focus on the practical aspect of implementing and training DCGAN, but not too much on the theoretical aspect. You will also need some prior experience with Python programming.
This course runs on Coursera's hands-on project platform called Rhyme. On Rhyme, you do projects in a hands-on manner in your browser. You will get instant access to pre-configured cloud desktops containing all of the software and data you need for the project. Everything is already set up directly in your internet browser so you can just focus on learning. For this project, you’ll get instant access to a cloud desktop with Python, Jupyter, and Tensorflow pre-installed.
Notes:
- You will be able to access the cloud desktop 5 times. However, you will be able to access instructions videos as many times as you want.
- This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Image Super Resolution Using Autoencoders in Keras
Welcome to this 1.5 hours long hands-on project on Image Super Resolution using Autoencoders in Keras. In this project, you’re going to learn what an autoencoder is, use Keras with Tensorflow as its backend to train your own autoencoder, and use this deep learning powered autoencoder to significantly enhance the quality of images. That is, our neural network will create high-resolution images from low-res source images.
This course runs on Coursera's hands-on project platform called Rhyme. On Rhyme, you do projects in a hands-on manner in your browser. You will get instant access to pre-configured cloud desktops containing all of the software and data you need for the project. Everything is already set up directly in your internet browser so you can just focus on learning. For this project, you’ll get instant access to a cloud desktop with Python, Jupyter, and Keras pre-installed.
Notes:
- You will be able to access the cloud desktop 5 times. However, you will be able to access instructions videos as many times as you want.
- This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
AI Workflow: Machine Learning, Visual Recognition and NLP
This is the fourth course in the IBM AI Enterprise Workflow Certification specialization. You are STRONGLY encouraged to complete these courses in order as they are not individual independent courses, but part of a workflow where each course builds on the previous ones.
Course 4 covers the next stage of the workflow, setting up models and their associated data pipelines for a hypothetical streaming media company. The first topic covers the complex topic of evaluation metrics, where you will learn best practices for a number of different metrics including regression metrics, classification metrics, and multi-class metrics, which you will use to select the best model for your business challenge. The next topics cover best practices for different types of models including linear models, tree-based models, and neural networks. Out-of-the-box Watson models for natural language understanding and visual recognition will be used. There will be case studies focusing on natural language processing and on image analysis to provide realistic context for the model pipelines.
By the end of this course you will be able to:
Discuss common regression, classification, and multilabel classification metrics
Explain the use of linear and logistic regression in supervised learning applications
Describe common strategies for grid searching and cross-validation
Employ evaluation metrics to select models for production use
Explain the use of tree-based algorithms in supervised learning applications
Explain the use of Neural Networks in supervised learning applications
Discuss the major variants of neural networks and recent advances
Create a neural net model in Tensorflow
Create and test an instance of Watson Visual Recognition
Create and test an instance of Watson NLU
Who should take this course?
This course targets existing data science practitioners that have expertise building machine learning models, who want to deepen their skills on building and deploying AI in large enterprises. If you are an aspiring Data Scientist, this course is NOT for you as you need real world expertise to benefit from the content of these courses.
What skills should you have?
It is assumed that you have completed Courses 1 through 3 of the IBM AI Enterprise Workflow specialization and you have a solid understanding of the following topics prior to starting this course: Fundamental understanding of Linear Algebra; Understand sampling, probability theory, and probability distributions; Knowledge of descriptive and inferential statistical concepts; General understanding of machine learning techniques and best practices; Practiced understanding of Python and the packages commonly used in data science: NumPy, Pandas, matplotlib, scikit-learn; Familiarity with IBM Watson Studio; Familiarity with the design thinking process.
AI Workflow: AI in Production
This is the sixth course in the IBM AI Enterprise Workflow Certification specialization. You are STRONGLY encouraged to complete these courses in order as they are not individual independent courses, but part of a workflow where each course builds on the previous ones.
This course focuses on models in production at a hypothetical streaming media company. There is an introduction to IBM Watson Machine Learning. You will build your own API in a Docker container and learn how to manage containers with Kubernetes. The course also introduces several other tools in the IBM ecosystem designed to help deploy or maintain models in production. The AI workflow is not a linear process so there is some time dedicated to the most important feedback loops in order to promote efficient iteration on the overall workflow.
By the end of this course you will be able to:
1. Use Docker to deploy a flask application
2. Deploy a simple UI to integrate the ML model, Watson NLU, and Watson Visual Recognition
3. Discuss basic Kubernetes terminology
4. Deploy a scalable web application on Kubernetes
5. Discuss the different feedback loops in AI workflow
6. Discuss the use of unit testing in the context of model production
7. Use IBM Watson OpenScale to assess bias and performance of production machine learning models.
Who should take this course?
This course targets existing data science practitioners that have expertise building machine learning models, who want to deepen their skills on building and deploying AI in large enterprises. If you are an aspiring Data Scientist, this course is NOT for you as you need real world expertise to benefit from the content of these courses.
What skills should you have?
It is assumed that you have completed Courses 1 through 5 of the IBM AI Enterprise Workflow specialization and you have a solid understanding of the following topics prior to starting this course: Fundamental understanding of Linear Algebra; Understand sampling, probability theory, and probability distributions; Knowledge of descriptive and inferential statistical concepts; General understanding of machine learning techniques and best practices; Practiced understanding of Python and the packages commonly used in data science: NumPy, Pandas, matplotlib, scikit-learn; Familiarity with IBM Watson Studio; Familiarity with the design thinking process.
Predict Ad Clicks Using Logistic Regression and XG-Boost
In this project, we will predict Ads clicks using logistic regression and XG-boost algorithms. In this project, we will assume that you have been hired as a consultant to a start-up that is running a targeted marketing ad campaign on Facebook. The company wants to analyze customer behavior by predicting which customer clicks on the advertisement.
Machine Learning: Clustering & Retrieval
Case Studies: Finding Similar Documents
A reader is interested in a specific news article and you want to find similar articles to recommend. What is the right notion of similarity? Moreover, what if there are millions of other documents? Each time you want to a retrieve a new document, do you need to search through all other documents? How do you group similar documents together? How do you discover new, emerging topics that the documents cover?
In this third case study, finding similar documents, you will examine similarity-based algorithms for retrieval. In this course, you will also examine structured representations for describing the documents in the corpus, including clustering and mixed membership models, such as latent Dirichlet allocation (LDA). You will implement expectation maximization (EM) to learn the document clusterings, and see how to scale the methods using MapReduce.
Learning Outcomes: By the end of this course, you will be able to:
-Create a document retrieval system using k-nearest neighbors.
-Identify various similarity metrics for text data.
-Reduce computations in k-nearest neighbor search by using KD-trees.
-Produce approximate nearest neighbors using locality sensitive hashing.
-Compare and contrast supervised and unsupervised learning tasks.
-Cluster documents by topic using k-means.
-Describe how to parallelize k-means using MapReduce.
-Examine probabilistic clustering approaches using mixtures models.
-Fit a mixture of Gaussian model using expectation maximization (EM).
-Perform mixed membership modeling using latent Dirichlet allocation (LDA).
-Describe the steps of a Gibbs sampler and how to use its output to draw inferences.
-Compare and contrast initialization techniques for non-convex optimization objectives.
-Implement these techniques in Python.
Popular Internships and Jobs by Categories
Find Jobs & Internships
Browse





© 2024 BoostGrad | All rights reserved