
Back to Courses







Machine Learning Courses - Page 28
Showing results 271-280 of 485
Employee Attrition Prediction Using Machine Learning
In this project-based course, we will build, train and test a machine learning model to predict employee attrition using features such as employee job satisfaction, distance from work, compensation and performance. We will explore two machine learning algorithms, namely: (1) logistic regression classifier model and (2) Extreme Gradient Boosted Trees (XG-Boost). This project could be effectively applied in any Human Resources department to predict which employees are more likely to quit based on their features.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Recommender Systems: Evaluation and Metrics
In this course you will learn how to evaluate recommender systems. You will gain familiarity with several families of metrics, including ones to measure prediction accuracy, rank accuracy, decision-support, and other factors such as diversity, product coverage, and serendipity. You will learn how different metrics relate to different user goals and business goals. You will also learn how to rigorously conduct offline evaluations (i.e., how to prepare and sample data, and how to aggregate results). And you will learn about online (experimental) evaluation. At the completion of this course you will have the tools you need to compare different recommender system alternatives for a wide variety of uses.
Leveraging Unstructured Data with Cloud Dataproc on Google Cloud em Português Brasileiro
Este curso intensivo de uma semana baseia-se nos cursos anteriores da especialização Data Engineering on Google Cloud Platform. Por meio de videoaulas, demonstrações e laboratórios práticos, você aprenderá a criar e gerenciar clusters de computação para executar jobs do Hadoop, Spark, Pig e/ou Hive no Google Cloud Platform.Você também aprenderá a acessar várias opções de armazenamento em nuvem dos clusters de computação e integrar os recursos de machine learning do Google aos respectivos programas de análise.
Nos laboratórios práticos, você criará e gerenciará os clusters do Dataproc usando o console da Web e a CLI e usará o cluster para executar jobs do Spark e Pig. Depois você criará notebooks iPython que são integrados ao BigQuery e ao armazenamento e utilizará o Spark. Por fim, você integrará as APIs de machine learning à análise de dados.
Pré-requisitos
• Noções básicas de Big Data e Machine Learning do Google Cloud Platform (ou experiência equivalente)
• Algum conhecimento de Python
Deep Learning for Business
Your smartphone, smartwatch, and automobile (if it is a newer model) have AI (Artificial Intelligence) inside serving you every day. In the near future, more advanced “self-learning” capable DL (Deep Learning) and ML (Machine Learning) technology will be used in almost every aspect of your business and industry. So now is the right time to learn what DL and ML is and how to use it in advantage of your company. This course has three parts, where the first part focuses on DL and ML technology based future business strategy including details on new state-of-the-art products/services and open source DL software, which are the future enablers. The second part focuses on the core technologies of DL and ML systems, which include NN (Neural Network), CNN (Convolutional NN), and RNN (Recurrent NN) systems. The third part focuses on four TensorFlow Playground projects, where experience on designing DL NNs can be gained using an easy and fun yet very powerful application called the TensorFlow Playground. This course was designed to help you build business strategies and enable you to conduct technical planning on new DL and ML services and products.
Machine Learning Under the Hood: The Technical Tips, Tricks, and Pitfalls
Machine learning. Your team needs it, your boss demands it, and your career loves it. After all, LinkedIn places it as one of the top few "Skills Companies Need Most" and as the very top emerging job in the U.S.
If you want to participate in the deployment of machine learning (aka predictive analytics), you've got to learn how it works. Even if you work as a business leader rather than a hands-on practitioner – even if you won't crunch the numbers yourself – you need to grasp the underlying mechanics in order to help navigate the overall project. Whether you're an executive, decision maker, or operational manager overseeing how predictive models integrate to drive decisions, the more you know, the better.
And yet, looking under the hood will delight you. The science behind machine learning intrigues and surprises, and an intuitive understanding is not hard to come by. With its impact on the world growing so quickly, it's time to demystify the predictive power of data – and how to scientifically tap it.
This course will show you how machine learning works. It covers the foundational underpinnings, the way insights are gleaned from data, how we can trust these insights are reliable, and how well predictive models perform – which can be established with pretty straightforward arithmetic. These are things every business professional needs to know, in addition to the quants.
And this course continues beyond machine learning standards to also cover cutting-edge, advanced methods, as well as preparing you to circumvent prevalent pitfalls that seldom receive the attention they deserve. The course dives deeply into these topics, and yet remains accessible to non-technical learners and newcomers.
With this course, you'll learn what works and what doesn't – the good, the bad, and the fuzzy:
– How predictive modeling algorithms work, including decision trees, logistic regression, and neural networks
– Treacherous pitfalls such as overfitting, p-hacking, and presuming causation from correlations
– How to interpret a predictive model in detail and explain how it works
– Advanced methods such as ensembles and uplift modeling (aka persuasion modeling)
– How to pick a tool, selecting from the many machine learning software options
– How to evaluate a predictive model, reporting on its performance in business terms
– How to screen a predictive model for potential bias against protected classes – aka AI ethics
IN-DEPTH YET ACCESSIBLE. Brought to you by industry leader Eric Siegel – a winner of teaching awards when he was a professor at Columbia University – this curriculum stands out as one of the most thorough, engaging, and surprisingly accessible on the subject of machine learning.
NO HANDS-ON AND NO HEAVY MATH. Rather than a hands-on training, this course serves both business leaders and burgeoning data scientists alike with expansive coverage of the state-of-the-art techniques and the most pernicious pitfalls. There are no exercises involving coding or the use of machine learning software. However, for one of the assessments, you'll perform a hands-on exercise, creating a predictive model by hand in Excel or Google Sheets and visualizing how it improves before your eyes.
BUT TECHNICAL LEARNERS SHOULD TAKE ANOTHER LOOK. Before jumping straight into the hands-on, as quants are inclined to do, consider one thing: This curriculum provides complementary know-how that all great techies also need to master. It contextualizes the core technology with a strong conceptual framework and covers topics that are generally omitted from even the most technical of courses, including uplift modeling (aka persuasion modeling) and some particularly treacherous pitfalls.
VENDOR-NEUTRAL. This course includes illuminating software demos of machine learning in action using SAS products. However, the curriculum is vendor-neutral and universally-applicable. The contents and learning objectives apply, regardless of which machine learning software tools you end up choosing to work with.
PREREQUISITES. Before this course, learners should take the first two of this specialization's three courses, "The Power of Machine Learning" and "Launching Machine Learning."
AI Applications in Marketing and Finance
In this course, you will learn about AI-powered applications that can enhance the customer journey and extend the customer lifecycle. You will learn how this AI-powered data can enable you to analyze consumer habits and maximize their potential to target your marketing to the right people. You will also learn about fraud, credit risks, and how AI applications can also help you combat the ever-challenging landscape of protecting consumer data. You will also learn methods to utilize supervised and unsupervised machine learning to enhance your fraud detection methods. You will also hear from leading industry experts in the world of data analytics, marketing, and fraud prevention. By the end of this course, you will have a substantial understanding of the role AI and Machine Learning play when it comes to consumer habits, and how we are able to interact and analyze information to increase deep learning potential for your business.
Getting Started with AI using IBM Watson
In this course you will learn how to quickly and easily get started with Artificial Intelligence using IBM Watson. You will understand how Watson works, become familiar with its use cases and real life client examples, and be introduced to several of Watson AI services from IBM that enable anyone to easily apply AI and build smart apps. You will also work with several Watson services to demonstrate AI in action.
This course does not require any programming or computer science expertise and is designed for anyone whether you have a technical background or not.
Build a Clustering Model using PyCaret
In this 1-hour long project-based course, you will create an end-to-end clustering model using PyCaret a low-code Python open-source Machine Learning library.
The goal is to build a model that can segment a wholesale customers based on their historical purchases.
You will learn how to automate the major steps for building, evaluating, comparing and interpreting Machine Learning Models for clustering.
Here are the main steps you will go through: frame the problem, get and prepare the data, discover and visualize the data, create the transformation pipeline, build, evaluate, interpret and deploy the model.
This guided project is for seasoned Data Scientists who want to build a accelerate the efficiency in building POC and experiments by using a low-code library. It is also for Citizen data Scientists (professionals working with data) by using the low-code library PyCaret to add machine learning models to the analytics toolkit.
To be successful in this project, you should be familiar with Python and the basic concepts on Machine Learning.
Logistic Regression for Classification using Julia
This guided project is about book genre classification using logistic regression in Julia. It is ideal for beginners who do not know what logistic regression is because this project explains these concepts in simple terms.
While you are watching me code, you will get a cloud desktop with all the required software pre-installed. This will allow you to code along with me. After all, we learn best with active, hands-on learning.
Special features:
1) Simple explanations of important concepts.
2) Use of images to aid in explanation.
3) Use a real world dataset.
Note: This project works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
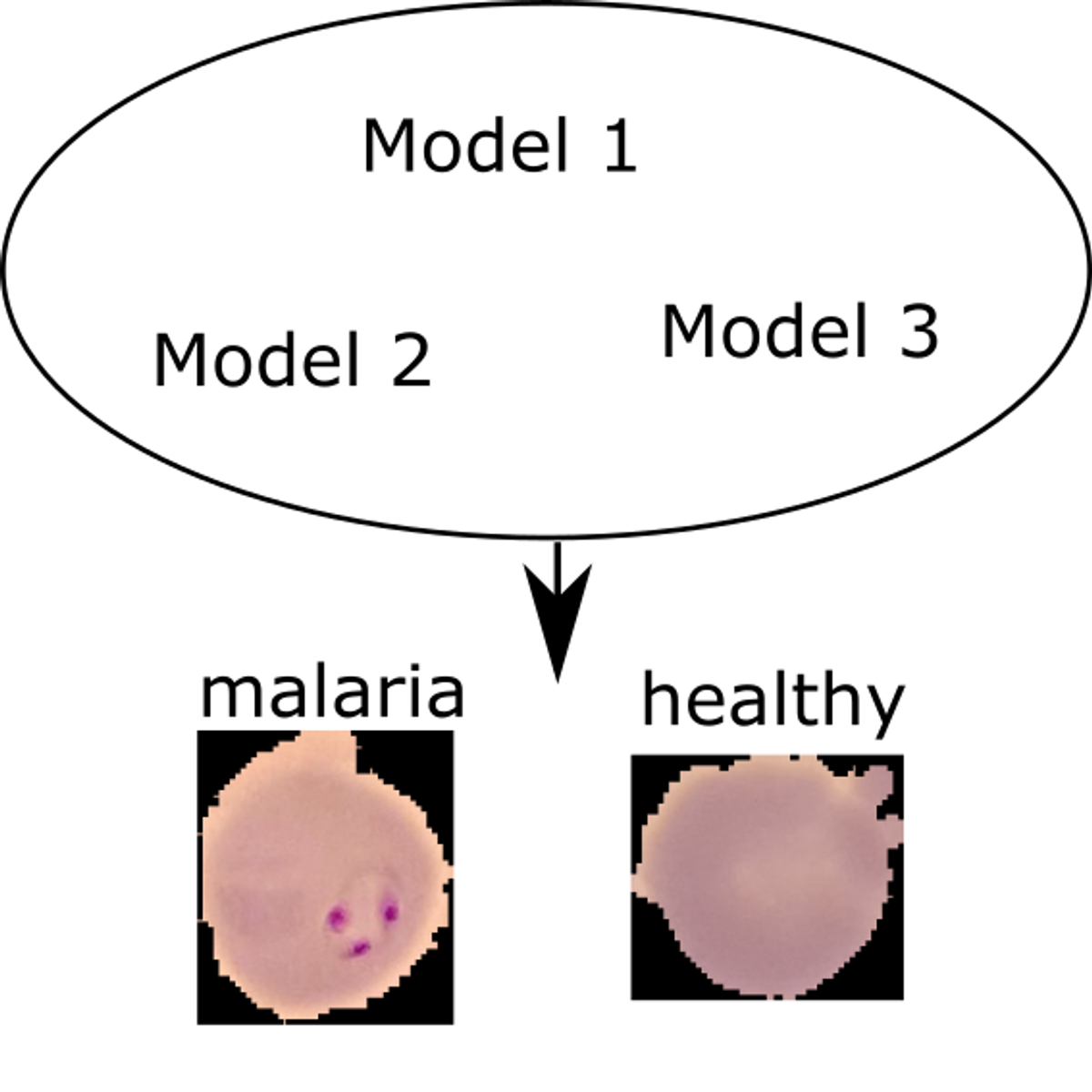
Malaria parasite detection using ensemble learning in Keras
In this 1-hour long project-based course, you will learn what ensemble learning is and how to implement is using python. You will create deep convolutional neural networks using the Keras library to predict the malaria parasite. You will learn various ways of assessing classification models. You will create an ensemble of deep convolutional neural networks and apply voting in order to combine the best predictions of your models.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Popular Internships and Jobs by Categories
Browse
© 2024 BoostGrad | All rights reserved