
Back to Courses






Machine Learning Courses - Page 27
Showing results 261-270 of 485
Explainable Machine Learning with LIME and H2O in R
Welcome to this hands-on, guided introduction to Explainable Machine Learning with LIME and H2O in R. By the end of this project, you will be able to use the LIME and H2O packages in R for automatic and interpretable machine learning, build classification models quickly with H2O AutoML and explain and interpret model predictions using LIME.
Machine learning (ML) models such as Random Forests, Gradient Boosted Machines, Neural Networks, Stacked Ensembles, etc., are often considered black boxes. However, they are more accurate for predicting non-linear phenomena due to their flexibility. Experts agree that higher accuracy often comes at the price of interpretability, which is critical to business adoption, trust, regulatory oversight (e.g., GDPR, Right to Explanation, etc.). As more industries from healthcare to banking are adopting ML models, their predictions are being used to justify the cost of healthcare and for loan approvals or denials. For regulated industries that use machine learning, interpretability is a requirement. As Finale Doshi-Velez and Been Kim put it, interpretability is "The ability to explain or to present in understandable terms to a human.".
To successfully complete the project, we recommend that you have prior experience with programming in R, basic machine learning theory, and have trained ML models in R.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Matrix Factorization and Advanced Techniques
In this course you will learn a variety of matrix factorization and hybrid machine learning techniques for recommender systems. Starting with basic matrix factorization, you will understand both the intuition and the practical details of building recommender systems based on reducing the dimensionality of the user-product preference space. Then you will learn about techniques that combine the strengths of different algorithms into powerful hybrid recommenders.
Probabilistic Deep Learning with TensorFlow 2
Welcome to this course on Probabilistic Deep Learning with TensorFlow!
This course builds on the foundational concepts and skills for TensorFlow taught in the first two courses in this specialisation, and focuses on the probabilistic approach to deep learning. This is an increasingly important area of deep learning that aims to quantify the noise and uncertainty that is often present in real world datasets. This is a crucial aspect when using deep learning models in applications such as autonomous vehicles or medical diagnoses; we need the model to know what it doesn't know.
You will learn how to develop probabilistic models with TensorFlow, making particular use of the TensorFlow Probability library, which is designed to make it easy to combine probabilistic models with deep learning. As such, this course can also be viewed as an introduction to the TensorFlow Probability library.
You will learn how probability distributions can be represented and incorporated into deep learning models in TensorFlow, including Bayesian neural networks, normalising flows and variational autoencoders. You will learn how to develop models for uncertainty quantification, as well as generative models that can create new samples similar to those in the dataset, such as images of celebrity faces.
You will put concepts that you learn about into practice straight away in practical, hands-on coding tutorials, which you will be guided through by a graduate teaching assistant. In addition there is a series of automatically graded programming assignments for you to consolidate your skills.
At the end of the course, you will bring many of the concepts together in a Capstone Project, where you will develop a variational autoencoder algorithm to produce a generative model of a synthetic image dataset that you will create yourself.
This course follows on from the previous two courses in the specialisation, Getting Started with TensorFlow 2 and Customising Your Models with TensorFlow 2. The additional prerequisite knowledge required in order to be successful in this course is a solid foundation in probability and statistics. In particular, it is assumed that you are familiar with standard probability distributions, probability density functions, and concepts such as maximum likelihood estimation, change of variables formula for random variables, and the evidence lower bound (ELBO) used in variational inference.
Machine Learning for Telecom Customers Churn Prediction
In this hands-on project, we will train several classification algorithms such as Logistic Regression, Support Vector Machine, K-Nearest Neighbors, and Random Forest Classifier to predict the churn rate of Telecommunication Customers. Machine learning help companies analyze customer churn rate based on several factors such as services subscribed by customers, tenure rate, and payment method. Predicting churn rate is crucial for these companies because the cost of retaining an existing customer is far less than acquiring a new one.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Probabilistic Graphical Models 3: Learning
Probabilistic graphical models (PGMs) are a rich framework for encoding probability distributions over complex domains: joint (multivariate) distributions over large numbers of random variables that interact with each other. These representations sit at the intersection of statistics and computer science, relying on concepts from probability theory, graph algorithms, machine learning, and more. They are the basis for the state-of-the-art methods in a wide variety of applications, such as medical diagnosis, image understanding, speech recognition, natural language processing, and many, many more. They are also a foundational tool in formulating many machine learning problems.
This course is the third in a sequence of three. Following the first course, which focused on representation, and the second, which focused on inference, this course addresses the question of learning: how a PGM can be learned from a data set of examples. The course discusses the key problems of parameter estimation in both directed and undirected models, as well as the structure learning task for directed models. The (highly recommended) honors track contains two hands-on programming assignments, in which key routines of two commonly used learning algorithms are implemented and applied to a real-world problem.
Build a Bot in Python for Basic File and Interface Chores
If your work causes you to find yourself constantly at a keyboard, then you know how tedious doing file system chores can be. From organizing files into folders, whether by file type, attributes, or simply alphabetically or by month, all of these tasks consume our time and increase the time required by other tasks. Yet, without organizing, searching for the correct files can steal just as much time.
What if you had a friend to help you out? In this project, I will show you step-by-step how to code an AI assistant that can accept simple commands and help you keep organized. By the time you're finished, you'll have a working prototype of a file helper bot that from the get-go will have the ability to clean and organize your files and folders the way you ask it to, combine text files into PDFs, search for files based on parameters set by you, and even search Google for answers. Your assistant will also be fully expandable, so you can write new methods to teach it new tasks!
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Optimize TensorFlow Models For Deployment with TensorRT
This is a hands-on, guided project on optimizing your TensorFlow models for inference with NVIDIA's TensorRT. By the end of this 1.5 hour long project, you will be able to optimize Tensorflow models using the TensorFlow integration of NVIDIA's TensorRT (TF-TRT), use TF-TRT to optimize several deep learning models at FP32, FP16, and INT8 precision, and observe how tuning TF-TRT parameters affects performance and inference throughput.
Prerequisites:
In order to successfully complete this project, you should be competent in Python programming, understand deep learning and what inference is, and have experience building deep learning models in TensorFlow and its Keras API.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Generate Synthetic Images with DCGANs in Keras
In this hands-on project, you will learn about Generative Adversarial Networks (GANs) and you will build and train a Deep Convolutional GAN (DCGAN) with Keras to generate images of fashionable clothes. We will be using the Keras Sequential API with Tensorflow 2 as the backend.
In our GAN setup, we want to be able to sample from a complex, high-dimensional training distribution of the Fashion MNIST images. However, there is no direct way to sample from this distribution. The solution is to sample from a simpler distribution, such as Gaussian noise. We want the model to use the power of neural networks to learn a transformation from the simple distribution directly to the training distribution that we care about. The GAN consists of two adversarial players: a discriminator and a generator. We’re going to train the two players jointly in a minimax game theoretic formulation.
This course runs on Coursera's hands-on project platform called Rhyme. On Rhyme, you do projects in a hands-on manner in your browser. You will get instant access to pre-configured cloud desktops containing all of the software and data you need for the project. Everything is already set up directly in your internet browser so you can just focus on learning. For this project, you’ll get instant access to a cloud desktop with Python, Jupyter, and Keras pre-installed.
Notes:
- You will be able to access the cloud desktop 5 times. However, you will be able to access instructions videos as many times as you want.
- This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
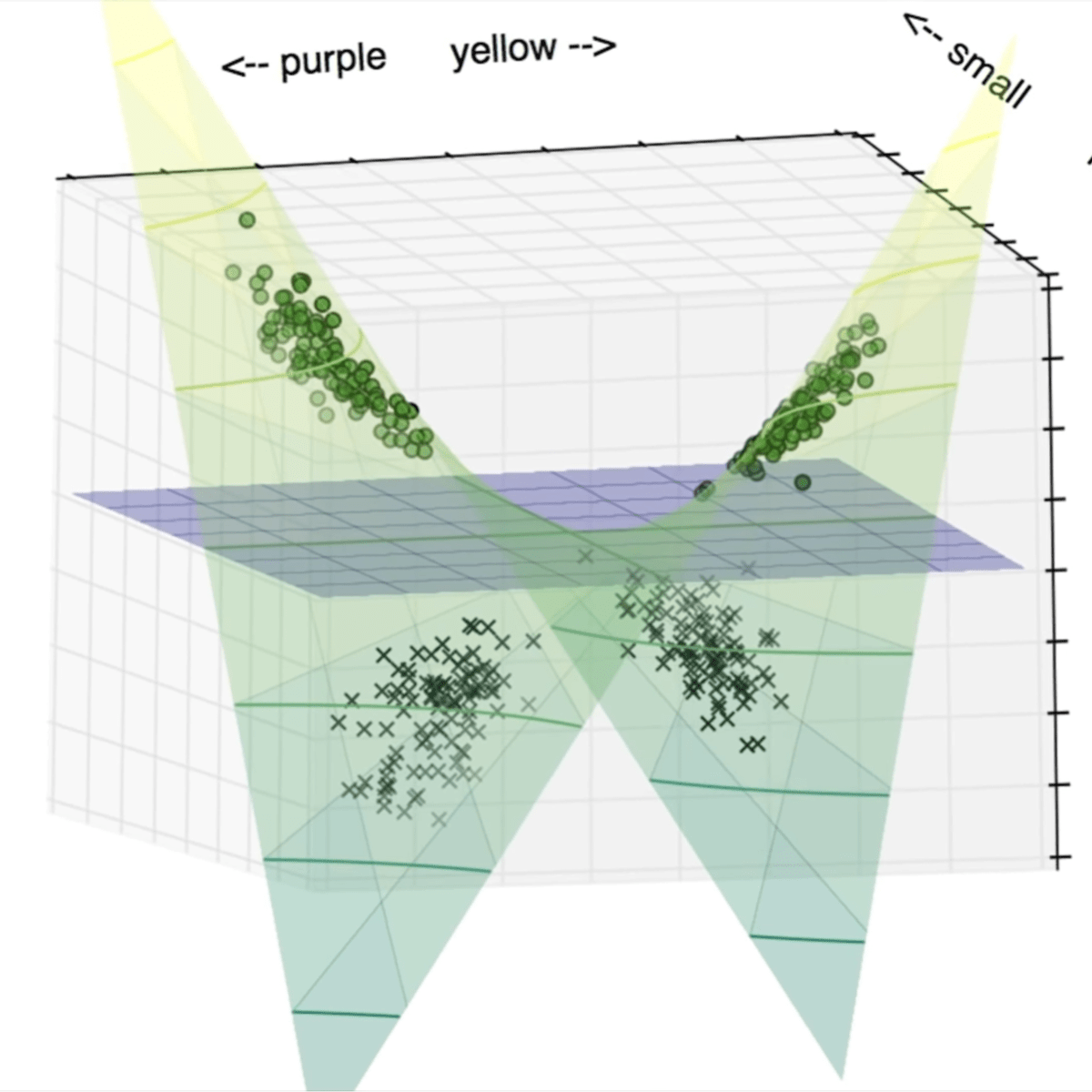
Non Linear SVM Classification -using SCKIT learn
Non Linear SVM Classification -using SCKIT learn
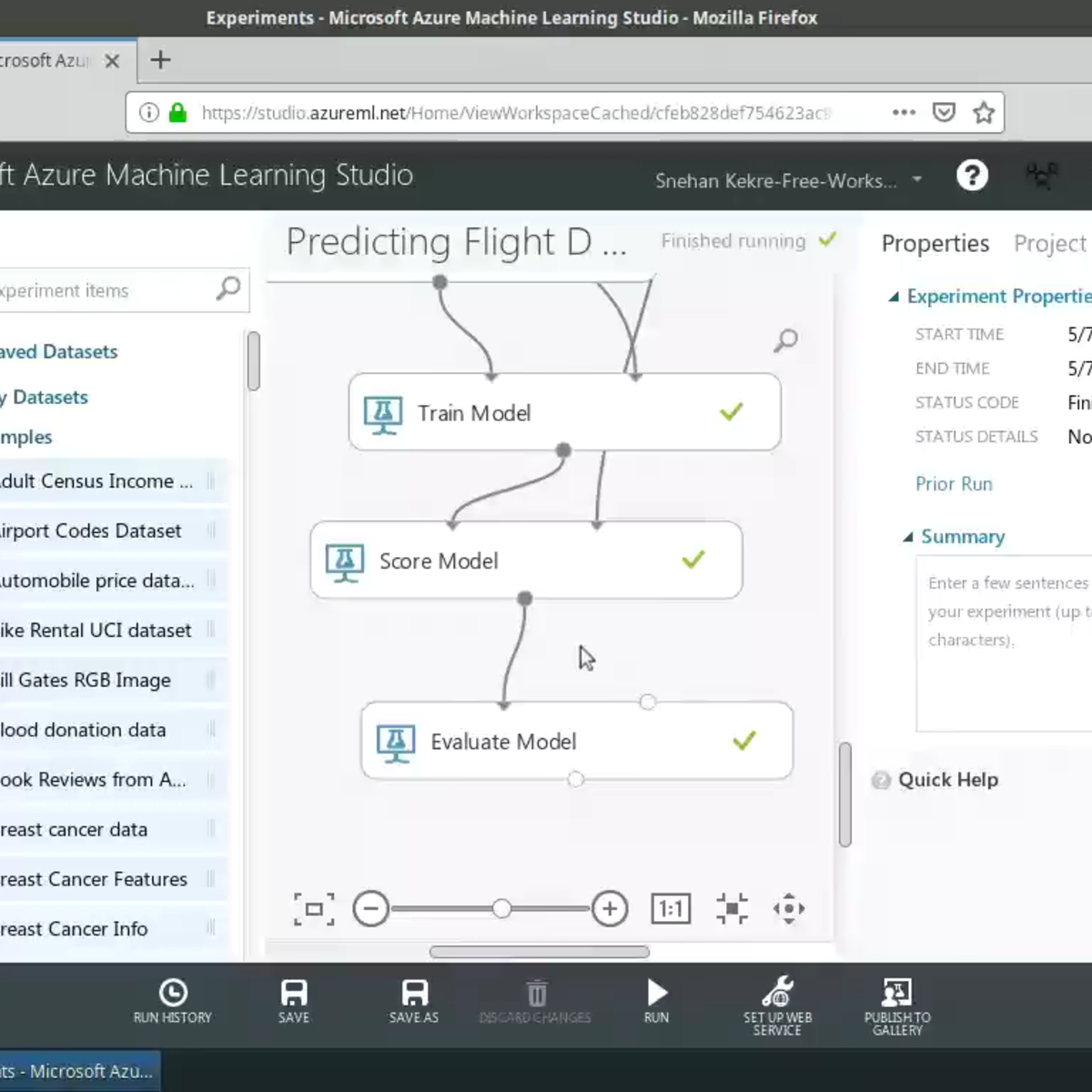
Predictive Modelling with Azure Machine Learning Studio
In this project, we will use Azure Machine Learning Studio to build a predictive model without writing a single line of code! Specifically, we will predict flight delays using weather data provided by the US Bureau of Transportation Statistics and the National Oceanic and Atmospheric Association (NOAA). You will be provided with instructions on how to set up your Azure Machine Learning account with $200 worth of free credit to get started with running your experiments!
This course runs on Coursera's hands-on project platform called Rhyme. On Rhyme, you do projects in a hands-on manner in your browser. You will get instant access to pre-configured cloud desktops containing all of the software and data you need for the project. Everything is already set up directly in your internet browser so you can just focus on learning. For this project, you’ll get instant access to a cloud desktop with Python, Jupyter, and scikit-learn pre-installed.
Notes:
- This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Popular Internships and Jobs by Categories
Browse
© 2024 BoostGrad | All rights reserved