
Back to Courses






Machine Learning Courses - Page 26
Showing results 251-260 of 485
Guided Tour of Machine Learning in Finance
This course aims at providing an introductory and broad overview of the field of ML with the focus on applications on Finance. Supervised Machine Learning methods are used in the capstone project to predict bank closures. Simultaneously, while this course can be taken as a separate course, it serves as a preview of topics that are covered in more details in subsequent modules of the specialization Machine Learning and Reinforcement Learning in Finance.
The goal of Guided Tour of Machine Learning in Finance is to get a sense of what Machine Learning is, what it is for and in how many different financial problems it can be applied to.
The course is designed for three categories of students:
Practitioners working at financial institutions such as banks, asset management firms or hedge funds
Individuals interested in applications of ML for personal day trading
Current full-time students pursuing a degree in Finance, Statistics, Computer Science, Mathematics, Physics, Engineering or other related disciplines who want to learn about practical applications of ML in Finance
Experience with Python (including numpy, pandas, and IPython/Jupyter notebooks), linear algebra, basic probability theory and basic calculus is necessary to complete assignments in this course.
Simple Nearest Neighbors Regression and Classification
In this 2-hour long project-based course, we will explore the basic principles behind the K-Nearest Neighbors algorithm, as well as learn how to implement KNN for decision making in Python.
A simple, easy-to-implement supervised machine learning algorithm that can be used to solve both classification and regression problems is the k-nearest neighbors (KNN) algorithm. The fundamental principle is that you enter a known data set, add an unknown data point, and the algorithm will tell you which class corresponds to that unknown data point. The unknown is characterized by a straightforward neighborly vote, where the "winner" class is the class of near neighbors. It is most commonly used for predictive decision-making. For instance,:
Is a consumer going to default on a loan or not?
Will the company make a profit?
Should we extend into a certain sector of the market?
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Logistic Regression with Python and Numpy
Welcome to this project-based course on Logistic with NumPy and Python. In this project, you will do all the machine learning without using any of the popular machine learning libraries such as scikit-learn and statsmodels. The aim of this project and is to implement all the machinery, including gradient descent, cost function, and logistic regression, of the various learning algorithms yourself, so you have a deeper understanding of the fundamentals. By the time you complete this project, you will be able to build a logistic regression model using Python and NumPy, conduct basic exploratory data analysis, and implement gradient descent from scratch. The prerequisites for this project are prior programming experience in Python and a basic understanding of machine learning theory.
This course runs on Coursera's hands-on project platform called Rhyme. On Rhyme, you do projects in a hands-on manner in your browser. You will get instant access to pre-configured cloud desktops containing all of the software and data you need for the project. Everything is already set up directly in your internet browser so you can just focus on learning. For this project, you’ll get instant access to a cloud desktop with Python, Jupyter, NumPy, and Seaborn pre-installed.
Advanced Machine Learning and Signal Processing
>>> By enrolling in this course you agree to the End User License Agreement as set out in the FAQ. Once enrolled you can access the license in the Resources area <<<
This course, Advanced Machine Learning and Signal Processing, is part of the IBM Advanced Data Science Specialization which IBM is currently creating and gives you easy access to the invaluable insights into Supervised and Unsupervised Machine Learning Models used by experts in many field relevant disciplines. We’ll learn about the fundamentals of Linear Algebra to understand how machine learning modes work. Then we introduce the most popular Machine Learning Frameworks for python Scikit-Learn and SparkML. SparkML is making up the greatest portion of this course since scalability is key to address performance bottlenecks. We learn how to tune the models in parallel by evaluating hundreds of different parameter-combinations in parallel. We’ll continuously use a real-life example from IoT (Internet of Things), for exemplifying the different algorithms. For passing the course you are even required to create your own vibration sensor data using the accelerometer sensors in your smartphone. So you are actually working on a self-created, real dataset throughout the course.
If you choose to take this course and earn the Coursera course certificate, you will also earn an IBM digital badge. To find out more about IBM digital badges follow the link ibm.biz/badging.
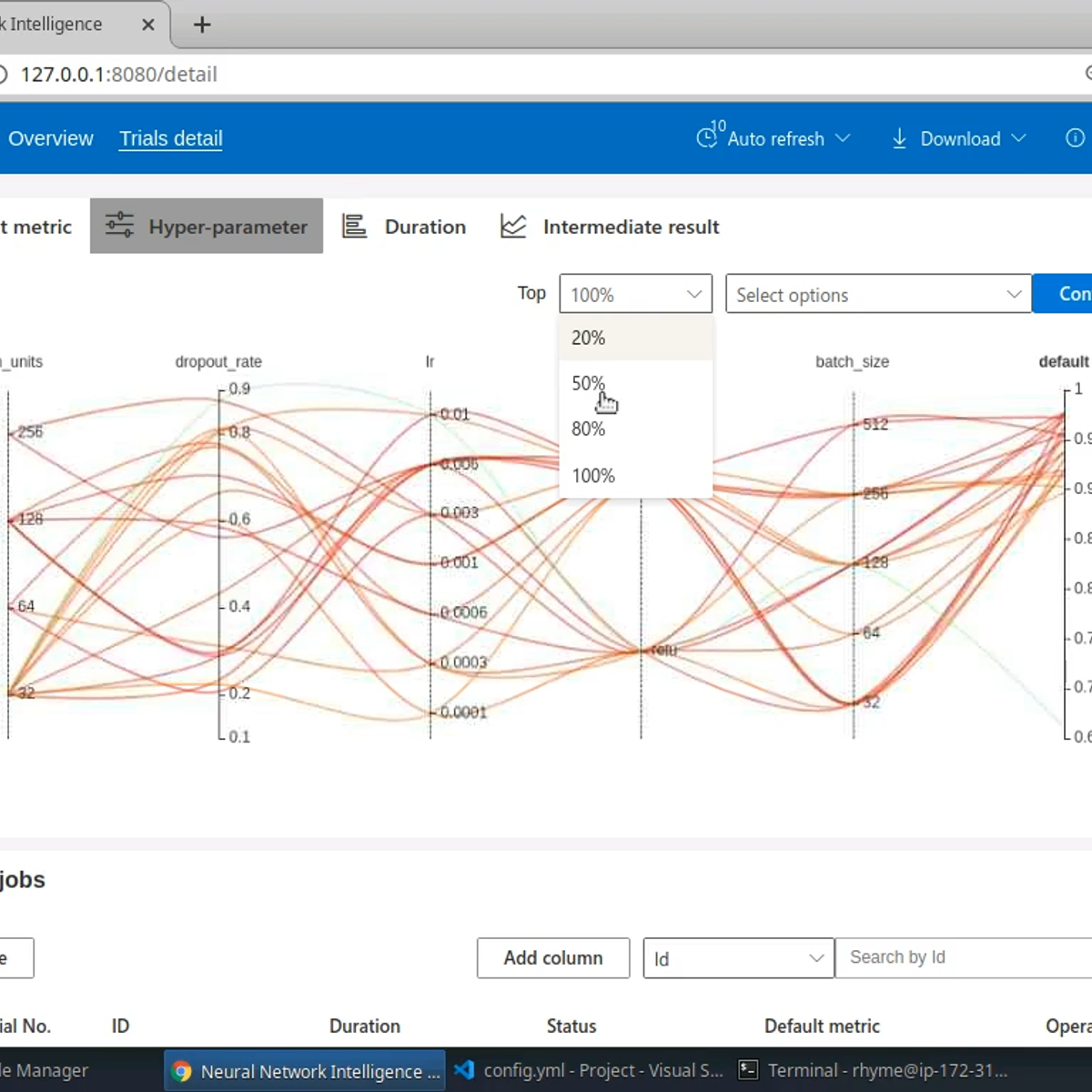
Hyperparameter Tuning with Neural Network Intelligence
In this 2-hour long guided project, we will learn the basics of using Microsoft's Neural Network Intelligence (NNI) toolkit and will use it to run a Hyperparameter tuning experiment on a Neural Network. NNI is an open source, AutoML toolkit created by Microsoft which can help machine learning practitioners automate Feature engineering, Hyperparameter tuning, Neural Architecture search and Model compression. In this guided project, we are going to take a look at using NNI to perform hyperparameter tuning. Please note that we are going to learn to use the NNI toolkit for hyperparameter tuning, and are not going to implement the tuning algorithms ourselves. We will use the popular MNIST dataset and train a simple Neural Network to learn to classify images of hand-written digits from the dataset. Once a basic script is in place, we will use the NNI toolkit to run a hyperparameter tuning experiment to find optimal values for batch size, learning rate, choice of activation function for the hidden layer, number of hidden units for the hidden layer, and dropout rate for the dropout layer.
To be able to complete this project successfully, you should be familiar with the Python programming language. You should also be familiar with Neural Networks, TensorFlow and Keras.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Predict Sales Revenue with scikit-learn
In this 2-hour long project-based course, you will build and evaluate a simple linear regression model using Python. You will employ the scikit-learn module for calculating the linear regression, while using pandas for data management, and seaborn for plotting. You will be working with the very popular Advertising data set to predict sales revenue based on advertising spending through mediums such as TV, radio, and newspaper.
By the end of this course, you will be able to:
- Explain the core ideas of linear regression to technical and non-technical audiences
- Build a simple linear regression model in Python with scikit-learn
- Employ Exploratory Data Analysis (EDA) to small data sets with seaborn and pandas
- Evaluate a simple linear regression model using appropriate metrics
This course runs on Coursera's hands-on project platform called Rhyme. On Rhyme, you will get instant access to pre-configured cloud desktops containing all of the software and data you need for the project. Everything is already set up directly in your internet browser so you can just focus on learning. For this project, you’ll get instant access to a cloud desktop with Jupyter and Python 3.7 with all the necessary libraries pre-installed.
Notes:
- You will be able to access the cloud desktop 5 times. However, you will be able to access instructions videos as many times as you want.
- This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Vertex Pipelines: Qwik Start
This is a self-paced lab that takes place in the Google Cloud console.
In this lab you will create ML Pipelines using Vertex AI. Pipelines help you automate and reproduce your ML workflow. Vertex AI integrates the ML offerings across Google Cloud into a seamless development experience. Previously, models trained with AutoML and custom models were accessible via separate services. Vertex AI combines both into a single API, along with other new products. Vertex AI also includes a variety of MLOps products, like Vertex Pipelines. In this lab, you will learn how to create and run ML pipelines with Vertex Pipelines.
Fine-tuning Convolutional Networks to Classify Dog Breeds
In this 2 hour-long project, you will learn how to approach an image classification task using TensorFlow. You will learn how to effectively preprocess your data to improve model generalizability, as well as build a performant modeling pipeline. Furthermore, you will learn how to accurately evaluate model performance using a confusion matrix; how to interpret results; and how to ask poignant questions about your dataset. Finally, you will fine-tune an existing, state-of-the-art-ready model to improve performance further.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Deep Neural Networks with PyTorch
The course will teach you how to develop deep learning models using Pytorch. The course will start with Pytorch's tensors and Automatic differentiation package. Then each section will cover different models starting off with fundamentals such as Linear Regression, and logistic/softmax regression. Followed by Feedforward deep neural networks, the role of different activation functions, normalization and dropout layers. Then Convolutional Neural Networks and Transfer learning will be covered. Finally, several other Deep learning methods will be covered.
Learning Outcomes:
After completing this course, learners will be able to:
• explain and apply their knowledge of Deep Neural Networks and related machine learning methods
• know how to use Python libraries such as PyTorch for Deep Learning applications
• build Deep Neural Networks using PyTorch
Advanced Manufacturing Process Analysis
Variability is a fact of life in manufacturing environments, impacting product quality and yield. Through this course, students will learn why performing advanced analysis of manufacturing processes is integral for diagnosing and correcting operational flaws in order to improve yields and reduce costs.
Gain insights into the best ways to collect, prepare and analyze data, as well as computational platforms that can be leveraged to collect and process data over sustained periods of time. Become better prepared to participate as a member of an advanced analysis team and share valuable inputs on effective implementation.
Main concepts of this course will be delivered through lectures, readings, discussions and various videos.
This is the fourth course in the Digital Manufacturing & Design Technology specialization that explores the many facets of manufacturing’s “Fourth Revolution,” aka Industry 4.0, and features a culminating project involving creation of a roadmap to achieve a self-established DMD-related professional goal. To learn more about the Digital Manufacturing and Design Technology specialization, please watch the overview video by copying and pasting the following link into your web browser: https://youtu.be/wETK1O9c-CA
Popular Internships and Jobs by Categories
Browse
© 2024 BoostGrad | All rights reserved