Back to Courses






Machine Learning Courses - Page 14
Showing results 131-140 of 485
AI Strategy and Governance
In this course, you will discover AI and the strategies that are used in transforming business in order to gain a competitive advantage. You will explore the multitude of uses for AI in an enterprise setting and the tools that are available to lower the barriers to AI use. You will get a closer look at the purpose, function, and use-cases for explainable AI. This course will also provide you with the tools to build responsible AI governance algorithms as faculty dive into the large datasets that you can expect to see in an enterprise setting and how that affects the business on a greater scale. Finally, you will examine AI in the organizational structure, how AI is playing a crucial role in change management, and the risks with AI processes. By the end of this course, you will learn different strategies to recognize biases that exist within data, how to ensure that you maintain and build trust with user data and privacy, and what it takes to construct a responsible governance strategy. For additional reading, Professor Hosanagar's book "A Human’s Guide to Machine Intelligence" can be used as an additional resource for more extensive information on topics covered in this module.
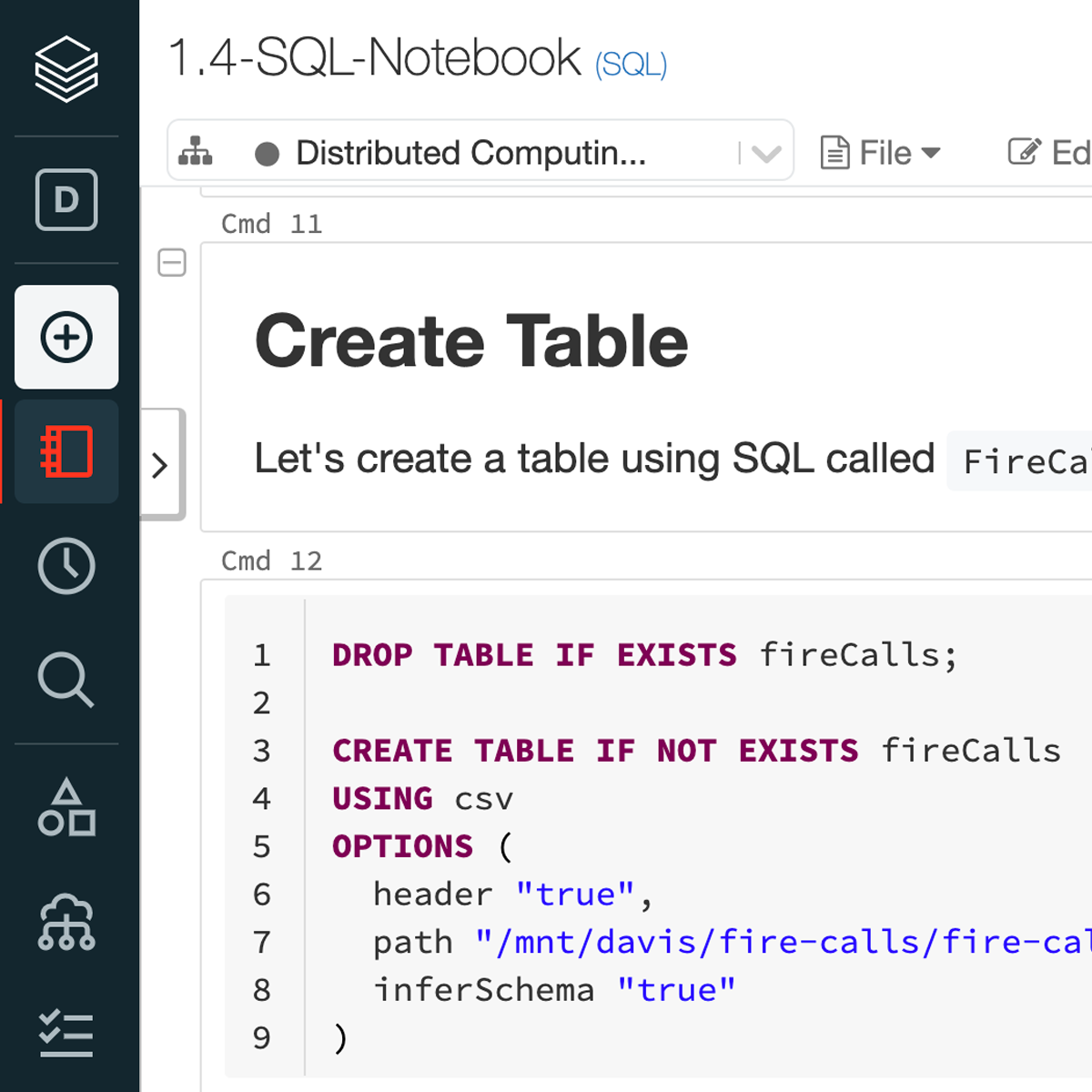
Distributed Computing with Spark SQL
This course is all about big data. It’s for students with SQL experience that want to take the next step on their data journey by learning distributed computing using Apache Spark. Students will gain a thorough understanding of this open-source standard for working with large datasets. Students will gain an understanding of the fundamentals of data analysis using SQL on Spark, setting the foundation for how to combine data with advanced analytics at scale and in production environments. The four modules build on one another and by the end of the course you will understand: the Spark architecture, queries within Spark, common ways to optimize Spark SQL, and how to build reliable data pipelines.
The first module introduces Spark and the Databricks environment including how Spark distributes computation and Spark SQL. Module 2 covers the core concepts of Spark such as storage vs. compute, caching, partitions, and troubleshooting performance issues via the Spark UI. It also covers new features in Apache Spark 3.x such as Adaptive Query Execution. The third module focuses on Engineering Data Pipelines including connecting to databases, schemas and data types, file formats, and writing reliable data. The final module covers data lakes, data warehouses, and lakehouses. Students build production grade data pipelines by combining Spark with the open-source project Delta Lake. By the end of this course, students will hone their SQL and distributed computing skills to become more adept at advanced analysis and to set the stage for transitioning to more advanced analytics as Data Scientists.
Support Vector Machine Classification in Python
In this 1-hour long guided project-based course, you will learn how to use Python to implement a Support Vector Machine algorithm for classification. This type of algorithm classifies output data and makes predictions. The output of this model is a set of visualized scattered plots separated with a straight line.
You will learn the fundamental theory and practical illustrations behind Support Vector Machines and learn to fit, examine, and utilize supervised Classification models using SVM to classify data, using Python.
We will walk you step-by-step into Machine Learning supervised problems. With every task in this project, you will expand your knowledge, develop new skills, and broaden your experience in Machine Learning.
Particularly, you will build a Support Vector Machine algorithm, and by the end of this project, you will be able to build your own SVM classification model with amazing visualization.
In order to be successful in this project, you should just know the basics of Python and classification algorithms.
Follow a Machine Learning Workflow
Machine learning is not just a single task or even a small group of tasks; it is an entire process, one that practitioners must follow from beginning to end. It is this process—also called a workflow—that enables the organization to get the most useful results out of their machine learning technologies. No matter what form the final product or service takes, leveraging the workflow is key to the success of the business's AI solution.
This second course within the Certified Artificial Intelligence Practitioner (CAIP) professional certificate explores each step along the machine learning workflow, from problem formulation all the way to model presentation and deployment. The overall workflow was introduced in the previous course, but now you'll take a deeper dive into each of the important tasks that make up the workflow, including two of the most hands-on tasks: data analysis and model training. You'll also learn about how machine learning tasks can be automated, ensuring that the workflow can recur as needed, like most important business processes.
Ultimately, this course provides a practical framework upon which you'll build many more machine learning models in the remaining courses.
Build Better Generative Adversarial Networks (GANs)
In this course, you will:
- Assess the challenges of evaluating GANs and compare different generative models
- Use the Fréchet Inception Distance (FID) method to evaluate the fidelity and diversity of GANs
- Identify sources of bias and the ways to detect it in GANs
- Learn and implement the techniques associated with the state-of-the-art StyleGANs
The DeepLearning.AI Generative Adversarial Networks (GANs) Specialization provides an exciting introduction to image generation with GANs, charting a path from foundational concepts to advanced techniques through an easy-to-understand approach. It also covers social implications, including bias in ML and the ways to detect it, privacy preservation, and more.
Build a comprehensive knowledge base and gain hands-on experience in GANs. Train your own model using PyTorch, use it to create images, and evaluate a variety of advanced GANs.
This Specialization provides an accessible pathway for all levels of learners looking to break into the GANs space or apply GANs to their own projects, even without prior familiarity with advanced math and machine learning research.
Basic Recommender Systems
This course introduces you to the leading approaches in recommender systems. The techniques described touch both collaborative and content-based approaches and include the most important algorithms used to provide recommendations. You'll learn how they work, how to use and how to evaluate them, pointing out benefits and limits of different recommender system alternatives.
After completing this course, you'll be able to describe the requirements and objectives of recommender systems based on different application domains. You'll know how to distinguish recommender systems according to their input data, their internal working mechanisms, and their goals. You’ll have the tools to measure the quality of a recommender system and to incrementally improve it with the design of new algorithms. You'll learn as well how to design recommender systems tailored for new application domains, also considering surrounding social and ethical issues such as identity, privacy, and manipulation.
Providing affordable, personalised and high-quality recommendations is always a challenge! This course also leverages two important EIT Overarching Learning Outcomes (OLOs), related to creativity and innovation skills. In trying to design a new recommender system you need to think beyond boundaries and try to figure out how you can improve the quality of the predictions. You should also be able to use knowledge, ideas and technology to create new or significantly improved recommendation tools to support choice-making processes and strategies in different and innovative scenarios, for a better quality of life.
Pneumonia Classification using PyTorch
In this 2-hour guided project, you are going to use EfficientNet model and train it on Pneumonia Chest X-Ray dataset. The dataset consist of nearly 5600 Chest X-Ray images and two categories (Pneumonia/Normal). Our main aim for this project is to build a pneumonia classifier which can classify Chest X-Ray scan that belong to one of the two classes. You will load and fine tune the pretrained EffiecientNet model and also to create a simple pytorch trainer to train the model.
In order to be successful in this project, you should be familiar with python, convolutional neural network, basic pytorch. This is a hands on, practical project that focuses primarily on implementation, and not on the theory behind Convolutional Neural Networks.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Handling Imbalanced Data Classification Problems
In this 2-hour long project-based course on handling imbalanced data classification problems, you will learn to understand the business problem related we are trying to solve and and understand the dataset. You will also learn how to select best evaluation metric for imbalanced datasets and data resampling techniques like undersampling, oversampling and SMOTE before we use them for model building process. At the end of the course you will understand and learn how to implement ROC curve and adjust probability threshold to improve selected evaluation metric of the model.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Supervised Machine Learning: Classification
This course introduces you to one of the main types of modeling families of supervised Machine Learning: Classification. You will learn how to train predictive models to classify categorical outcomes and how to use error metrics to compare across different models. The hands-on section of this course focuses on using best practices for classification, including train and test splits, and handling data sets with unbalanced classes.
By the end of this course you should be able to:
-Differentiate uses and applications of classification and classification ensembles
-Describe and use logistic regression models
-Describe and use decision tree and tree-ensemble models
-Describe and use other ensemble methods for classification
-Use a variety of error metrics to compare and select the classification model that best suits your data
-Use oversampling and undersampling as techniques to handle unbalanced classes in a data set
Who should take this course?
This course targets aspiring data scientists interested in acquiring hands-on experience with Supervised Machine Learning Classification techniques in a business setting.
What skills should you have?
To make the most out of this course, you should have familiarity with programming on a Python development environment, as well as fundamental understanding of Data Cleaning, Exploratory Data Analysis, Calculus, Linear Algebra, Probability, and Statistics.
Linear Regression with Python
In this 2-hour long project-based course, you will learn how to implement Linear Regression using Python and Numpy. Linear Regression is an important, fundamental concept if you want break into Machine Learning and Deep Learning. Even though popular machine learning frameworks have implementations of linear regression available, it's still a great idea to learn to implement it on your own to understand the mechanics of optimization algorithm, and the training process.
Since this is a practical, project-based course, you will need to have a theoretical understanding of linear regression, and gradient descent. We will focus on the practical aspect of implementing linear regression with gradient descent, but not on the theoretical aspect.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Popular Internships and Jobs by Categories
Find Jobs & Internships
Browse





© 2024 BoostGrad | All rights reserved