
Back to Courses







Data Analysis Courses - Page 91
Showing results 901-910 of 998
Research Data Management and Sharing
This course will provide learners with an introduction to research data management and sharing. After completing this course, learners will understand the diversity of data and their management needs across the research data lifecycle, be able to identify the components of good data management plans, and be familiar with best practices for working with data including the organization, documentation, and storage and security of data. Learners will also understand the impetus and importance of archiving and sharing data as well as how to assess the trustworthiness of repositories.
Today, an increasing number of funding agencies, journals, and other stakeholders are requiring data producers to share, archive, and plan for the management of their data. In order to respond to these requirements, researchers and information professionals will need the data management and curation knowledge and skills that support the long-term preservation, access, and reuse of data. Effectively managing data can also help optimize research outputs, increase the impact of research, and support open scientific inquiry. After completing this course, learners will be better equipped to manage data throughout the entire research data lifecycle from project planning to the end of the project when data ideally are shared and made available within a trustworthy repository.
This course was developed by the Curating Research Assets and Data Using Lifecycle Education (CRADLE) Project in collaboration with EDINA at the University of Edinburgh.
This course was made possible in part by the Institute of Museum and Library Services under award #RE-06-13-0052-13. The views, findings, conclusions or recommendations expressed in this Research Data Management and Sharing MOOC do not necessarily represent those of the Institute of Museum and Library Services.
Hashtag: #RDMSmooc
Leveraging Real-Time Analytics in Slack
By the end of this course, you will access and leverage analytics in Slack. Leveraging analytics in your Slack digital work environment will allow you to make data-driven decisions, foster a feedback culture, and define tactics that move your work group closer to its goals. You will do this by gaining hands-on experience accessing Slack’s internal analytics, reviewing external integrations and how they work in concert with them, and building an integration to the SurveyMonkey application from within Slack.
You will also have the opportunity to set up a free SurveyMonkey account to begin capturing new data from the team in your Slack workspace. Your hands-on project will include techniques that will enable you to integrate any cloud-based/outside service within your Slack environment and then leverage its functions and resources to maximize the effectiveness of collaborations and your team’s productivity through the practice of making data-driven decisions. For the purpose of this course, we will use the free-to-use, SurveyMonkey external integration and set it up from within your Slack environment.
You will work through this guided project in the Slack app on your Rhyme virtual machine, where you will use your current Slack workspace or set up a sample workspace under Slack’s free plan so that you can gain hands-on experience leveraging analytics in Slack with local and external integrations.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Spreadsheets for Beginners using Google Sheets
This 2-hour long project-based course is an introduction to spreadsheets. We’ll be using Google Sheets in this project, which is the free spreadsheet program offered by Google. With that said, most of the concepts that you will learn in this project will be applicable to other spreadsheet programs, such as Microsoft Excel.
We will cover the following concepts in a hands-on manner:
- Basic data entry, formatting and calculations
- Relative and absolute cell references
- Basic functions: concatenate, split, sum, average, median, min, max, count, counta
- Advanced functions: vlookup, if, and, or, iferror, countif, countifs, averageif, averageifs, sumif, sumifs
- Dealing with error messages
- Conditional formatting
- Filtering and sorting
- Basic charts to visualize our data
We will end the project by applying these concepts and create a basic spreadsheet model that helps us analyze household expenses.
Note: If you don't have a Google account, you will need to create one to be able to complete the content.
IBM Data Analyst Capstone Project
In this course you will apply various Data Analytics skills and techniques that you have learned as part of the previous courses in the IBM Data Analyst Professional Certificate. You will assume the role of an Associate Data Analyst who has recently joined the organization and be presented with a business challenge that requires data analysis to be performed on real-world datasets.
You will undertake the tasks of collecting data from multiple sources, performing exploratory data analysis, data wrangling and preparation, statistical analysis and mining the data, creating charts and plots to visualize data, and building an interactive dashboard. The project will culminate with a presentation of your data analysis report, with an executive summary for the various stakeholders in the organization. You will be assessed on both your work for the various stages in the Data Analysis process, as well as the final deliverable.
This project is a great opportunity to showcase your Data Analytics skills, and demonstrate your proficiency to potential employers.
Google Cloud Pub/Sub: Qwik Start - Console
This is a self-paced lab that takes place in the Google Cloud console. This hands-on lab shows you how to publish and consume messages with a pull subscriber, using the Google Cloud Platform Console. Watch the short video Simplify Event Driven Processing with Cloud Pub/Sub.
Calculus through Data & Modelling: Integration Applications
This course continues your study of calculus by focusing on the applications of integration. The applications in this section have many common features. First, each is an example of a quantity that is computed by evaluating a definite integral. Second, the formula for that application is derived from Riemann sums.
Rather than measure rates of change as we did with differential calculus, the definite integral allows us to measure the accumulation of a quantity over some interval of input values. This notion of accumulation can be applied to different quantities, including money, populations, weight, area, volume, and air pollutants. The concepts in this course apply to many other disciplines outside of traditional mathematics.
We will expand the notion of the average value of a data set to allow for infinite values, develop the formula for arclength and curvature, and derive formulas for velocity, acceleration, and areas between curves. Through examples and projects, we will apply the tools of this course to analyze and model real world data.
Serverless Data Processing with Dataflow: Foundations
This course is part 1 of a 3-course series on Serverless Data Processing with Dataflow. In this first course, we start with a refresher of what Apache Beam is and its relationship with Dataflow. Next, we talk about the Apache Beam vision and the benefits of the Beam Portability framework. The Beam Portability framework achieves the vision that a developer can use their favorite programming language with their preferred execution backend. We then show you how Dataflow allows you to separate compute and storage while saving money, and how identity, access, and management tools interact with your Dataflow pipelines. Lastly, we look at how to implement the right security model for your use case on Dataflow.
Prerequisites:
The Serverless Data Processing with Dataflow course series builds on the concepts covered in the Data Engineering specialization. We recommend the following prerequisite courses:
(i)Building batch data pipelines on Google Cloud : covers core Dataflow principles
(ii)Building Resilient Streaming Analytics Systems on Google Cloud : covers streaming basics concepts like windowing, triggers, and watermarks
>>> By enrolling in this course you agree to the Qwiklabs Terms of Service as set out in the FAQ and located at: https://qwiklabs.com/terms_of_service <<<
Fundamentals of Data Visualization
Data is everywhere. Charts, graphs, and other types of information visualizations help people to make sense of this data. This course explores the design, development, and evaluation of such information visualizations. By combining aspects of design, computer graphics, HCI, and data science, you will gain hands-on experience with creating visualizations, using exploratory tools, and architecting data narratives. Topics include user-centered design, web-based visualization, data cognition and perception, and design evaluation.
This course can be taken for academic credit as part of CU Boulder’s Master of Science in Data Science (MS-DS) degree offered on the Coursera platform. The MS-DS is an interdisciplinary degree that brings together faculty from CU Boulder’s departments of Applied Mathematics, Computer Science, Information Science, and others. With performance-based admissions and no application process, the MS-DS is ideal for individuals with a broad range of undergraduate education and/or professional experience in computer science, information science, mathematics, and statistics. Learn more about the MS-DS program at https://www.coursera.org/degrees/master-of-science-data-science-boulder.
Predict Diabetes with a Random Forest using R
In this 1-hour long project-based course, you will learn how to (complete a training and test set using an R function, practice looking at data distribution using R and ggplot2, Apply a Random Forest model to the data, and examine the results using RMSE and a Confusion Matrix).
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
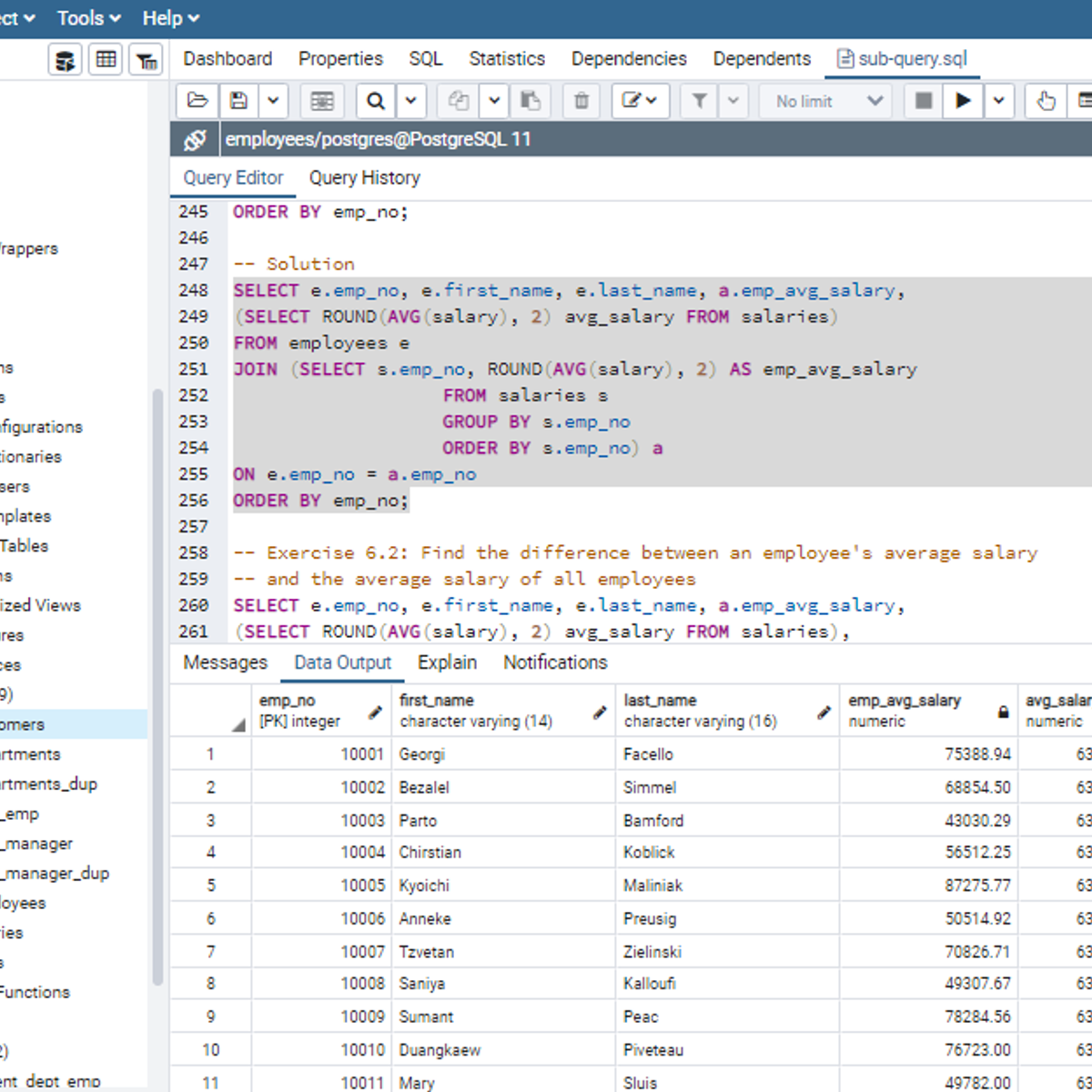
Working with Subqueries in SQL
Welcome to this project-based course, Working with Subqueries in SQL. In this project, you will learn how to use SQL subqueries extensively to query tables in a database.
By the end of this 2-and-a-half-hour-long project, you will be able to use subqueries in the WHERE clause, FROM clause, and the SELECT clause to retrieve the desired result from a database. In this project, we will move systematically by first introducing the use of subqueries in the WHERE clause. Then, we will use subqueries in the FROM and SELECT clause by writing slightly complex queries for real-life applications. Be assured that you will get your hands really dirty in this project because you will get to work on a lot of exercises to reinforce your knowledge of the concept.
Also, for this hands-on project, we will use PostgreSQL as our preferred database management system (DBMS). Therefore, to complete this project, it is required that you have prior experience with using PostgreSQL. Similarly, this project is an advanced SQL concept; so, a good foundation for writing SQL queries is vital to complete this project.
If you are not familiar with writing queries in SQL and want to learn these concepts, start with my previous guided projects titled “Querying Databases using SQL SELECT statement," and “Mastering SQL Joins.” I taught these guided projects using PostgreSQL. So, taking these projects will give the needed requisite to complete this Working with Subqueries in SQL project. However, if you are comfortable writing queries in PostgreSQL, please join me on this wonderful ride! Let’s get our hands dirty!
Popular Internships and Jobs by Categories
Browse
© 2024 BoostGrad | All rights reserved