
Back to Courses







Data Analysis Courses - Page 72
Showing results 711-720 of 998
Computational Social Science Capstone Project
CONGRATULATIONS! Not only did you accomplish to finish our intellectual tour de force, but, by now, you also already have all required skills to execute a comprehensive multi-method workflow of computational social science. We will put these skills to work in this final integrative lab, where we are bringing it all together. We scrape data from a social media site (drawing on the skills obtained in the 1st course of this specialization). We then analyze the collected data by visualizing the resulting networks (building on the skills obtained in the 3rd course). We analyze some key aspects of it in depth, using machine learning powered natural language processing (putting to work the insights obtained during the 2nd course). Finally, we use a computer simulation model to explore possible generative mechanism and scrutinize aspects that we did not find in our empirical reality, but that help us to improve this aspect of society (drawing on the skills obtained during the 4th course of this specialization). The result is the first glimpse at a new way of doing social science in a digital age: computational social science. Congratulations! Having done all of this yourself, you can consider yourself a fledgling computational social scientist!
Aggregate Data with LibreOffice Base Queries
By the end of this project, you will have written LibreOffice Base queries to retrieve and aggregate data from a Sales database. Using both the Query Design tool and the SQL View you will group and summarize data using functions such as: Sum, Average, Count, Min and Max. Aggregating (grouping and summarizing) data can significantly increase its value when provided to users for use in analysis.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Practical Python for AI Coding 2
Introduction video : https://youtu.be/TRhwIHvehR0
This course is for a complete novice of Python coding, so no prior knowledge or experience in software coding is required. This course selects, introduces and explains Python syntaxes, functions and libraries that were frequently used in AI coding. In addition, this course introduces vital syntaxes, and functions often used in AI coding and explains the complementary relationship among NumPy, Pandas and TensorFlow, so this course is helpful for even seasoned python users. This course starts with building an AI coding environment without failures on learners’ desktop or notebook computers to enable them to start AI modeling and coding with Scikit-learn, TensorFlow and Keras upon completing this course. Because learners have an AI coding environment on their computers after taking this course, they can start AI coding and do not need to join or use the cloud-based services.
Compare Models with Experiments in Azure ML Studio
Did you know that you can compare models in Azure Machine Learning?
In this 1-hour project-based course, you will learn how to log plots in experiments, log numeric metrics in experiments and visualize metrics in Azure Machine Learning Studio. To achieve this, we will use one example data, train a couple of machine learning algorithms in Jupyter notebook and visualize their results in Azure Machine Learning Studio Portal interface.
In order to be successful in this project, you will need knowledge of Python language and experience with machine learning in Python. Also, Azure subscription is required (free trial is an option for those who don’t have it), as well as Azure Machine Learning resource and a compute instance within. Instructional links will be provided to guide you through creation, if needed, in the first task.
If you are ready to make your experience training models simpler and more enjoyable, this is a course for you!
Let’s get started!
Natural Language Processing and Capstone Assignment
Welcome to Natural Language Processing and Capstone Assignment. In this course we will begin with an Recognize how technical and business techniques can be used to deliver business insight, competitive intelligence, and consumer sentiment. The course concludes with a capstone assignment in which you will apply a wide range of what has been covered in this specialization.
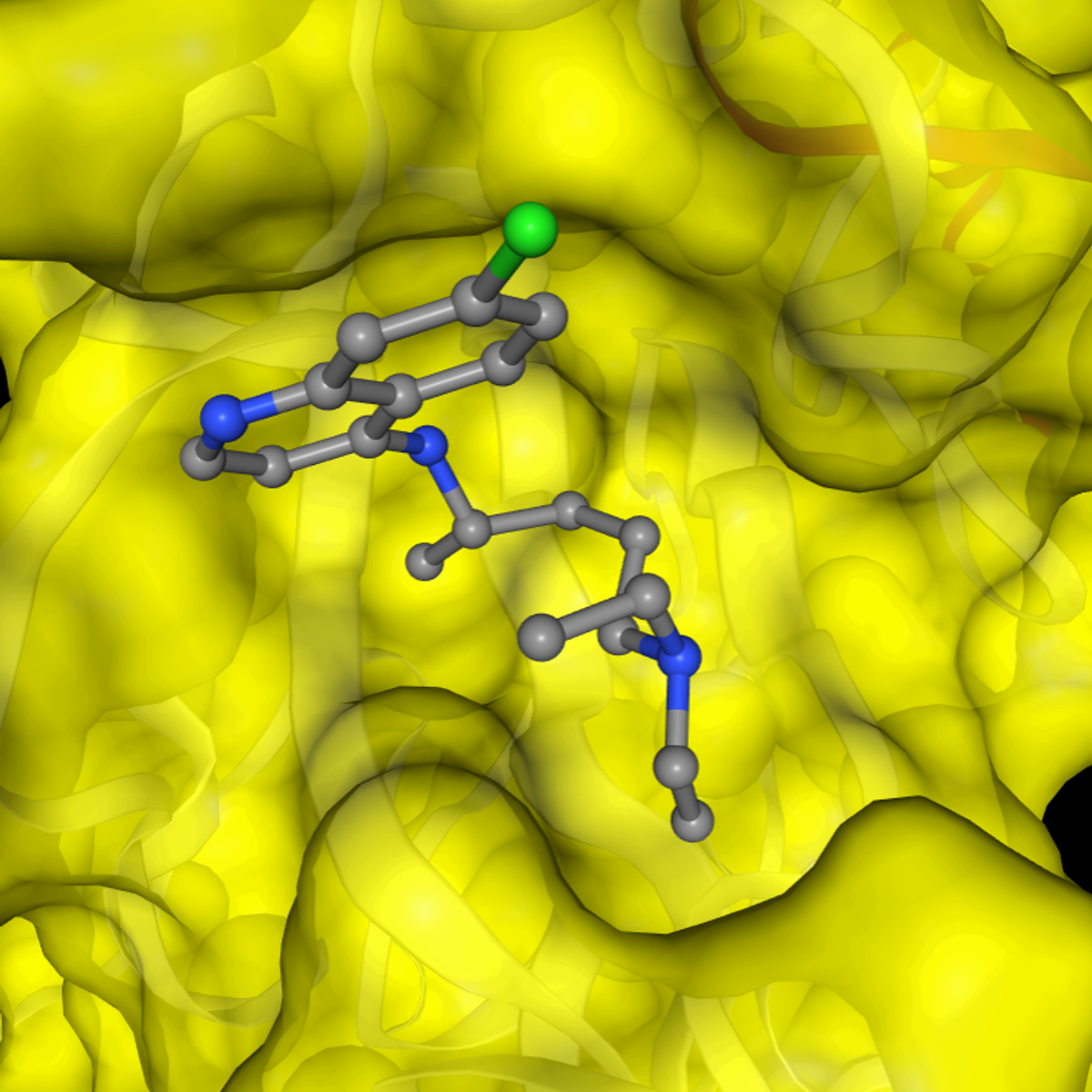
SARS-CoV-2 Protein Modeling and Drug Docking
In this 1-hour long project-based course, you will construct a 3D structure of a SARS-CoV-2 protein sequence using homology modeling and perform molecular docking of drugs against this protein molecule and infer protein-drug interaction. We will accomplish it in by completing each task in the project which includes
- Model protein structures from sequence data
- Process proteins and ligands for docking procedure
- Molecular docking of drugs against protein molecules
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Microsoft Azure for Data Engineering
The world of data has evolved and the advent of cloud technologies is providing new opportunities for businesses to explore. In this course, you will learn the various data platform technologies available, and how a Data Engineer can take advantage of this technology to an organization's benefit.
This course part of a Specialization intended for Data engineers and developers who want to demonstrate their expertise in designing and implementing data solutions that use Microsoft Azure data services anyone interested in preparing for the Exam DP-203: Data Engineering on Microsoft Azure (beta).
This is the first course in a program of 10 courses to help prepare you to take the exam so that you can have expertise in designing and implementing data solutions that use Microsoft Azure data services. The Data Engineering on Microsoft Azure exam is an opportunity to prove knowledge expertise in integrating, transforming, and consolidating data from various structured and unstructured data systems into structures that are suitable for building analytics solutions that use Microsoft Azure data services. Each course teaches you the concepts and skills that are measured by the exam.
By the end of this Specialization, you will be ready to take and sign-up for the Exam DP-203: Data Engineering on Microsoft Azure (beta).
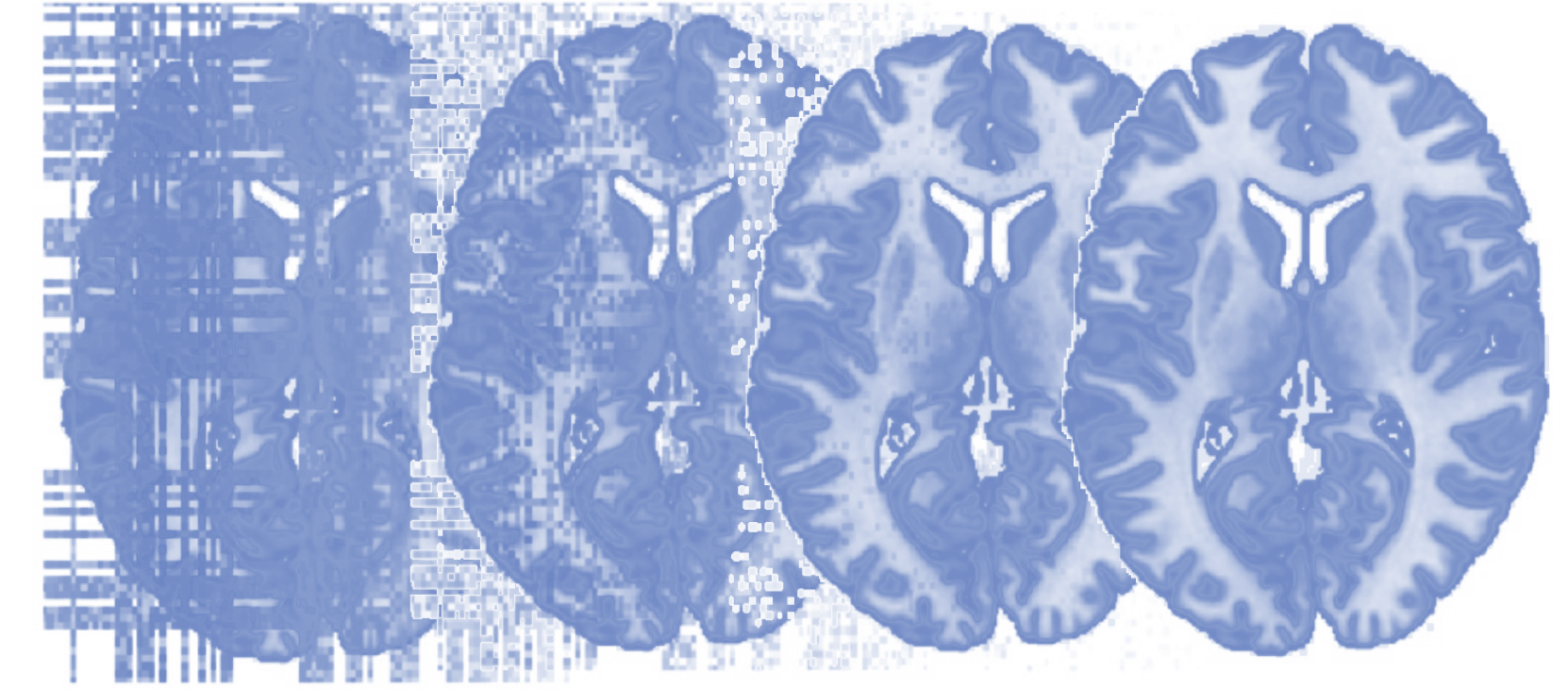
Principles of fMRI 1
Functional Magnetic Resonance Imaging (fMRI) is the most widely used technique for investigating the living, functioning human brain as people perform tasks and experience mental states. It is a convergence point for multidisciplinary work from many disciplines. Psychologists, statisticians, physicists, computer scientists, neuroscientists, medical researchers, behavioral scientists, engineers, public health researchers, biologists, and others are coming together to advance our understanding of the human mind and brain. This course covers the design, acquisition, and analysis of Functional Magnetic Resonance Imaging (fMRI) data, including psychological inference, MR Physics, K Space, experimental design, pre-processing of fMRI data, as well as Generalized Linear Models (GLM’s). A book related to the class can be found here: https://leanpub.com/principlesoffmri.
Database Architecture, Scale, and NoSQL with Elasticsearch
In this final course, you will explore database architecture, PostgreSQL, and various scalable deployment configurations. You will see how PostgreSQL implements basic CRUD operations and indexes, and review how transactions and the ACID (Atomicity, Consistency, Isolation, Durability) requirements are implemented.
You’ll learn to use Elasticsearch NoSQL, which is a common NoSQL database and a supplement to a relational database to high-speed search and indexing. We will examine Elasticsearch as an example of a BASE-style (Basic Availability, Soft State, Eventual Consistency) database approach, as well as compare and contrast the advantages and challenges associated with ACID and BASE databases.
High Throughput Databases with Microsoft Azure Cosmos DB
By the end of this guided project, you will have successfully created an Azure account, logged into the Azure Portal and created, and configured a new Azure Cosmos DB Account, You will have created a Cosmos DB Database and Containers and imported sample data, tested the import by running queries against the database using a Cosmos DB Notebook. You will also have configured both Manual and autoscale throughput against Databases and individual containers and configured request units or RUs Having successfully configured throughput you will have made the database globally accessible by creating a Read replica in a different region thus providing near user access to the data and also high availability. You will have completed this project by then deleting any non required resources to keep costs to a minimum.
If you enjoy this project, we recommend taking the Microsoft Azure Data Fundamentals DP-900 Exam Prep Specialization: https://www.coursera.org/specializations/microsoft-azure-dp-900-data-fundamentals
Popular Internships and Jobs by Categories
Browse
© 2024 BoostGrad | All rights reserved