
Back to Courses








Data Analysis Courses - Page 16
Showing results 151-160 of 998
Getting Started with SAS Visual Analytics
In this course, you learn more about SAS Visual Analytics and the SAS Viya platform, how to access and investigate data in SAS Visual Analytics, and how to prepare data for analysis using SAS Data Studio.
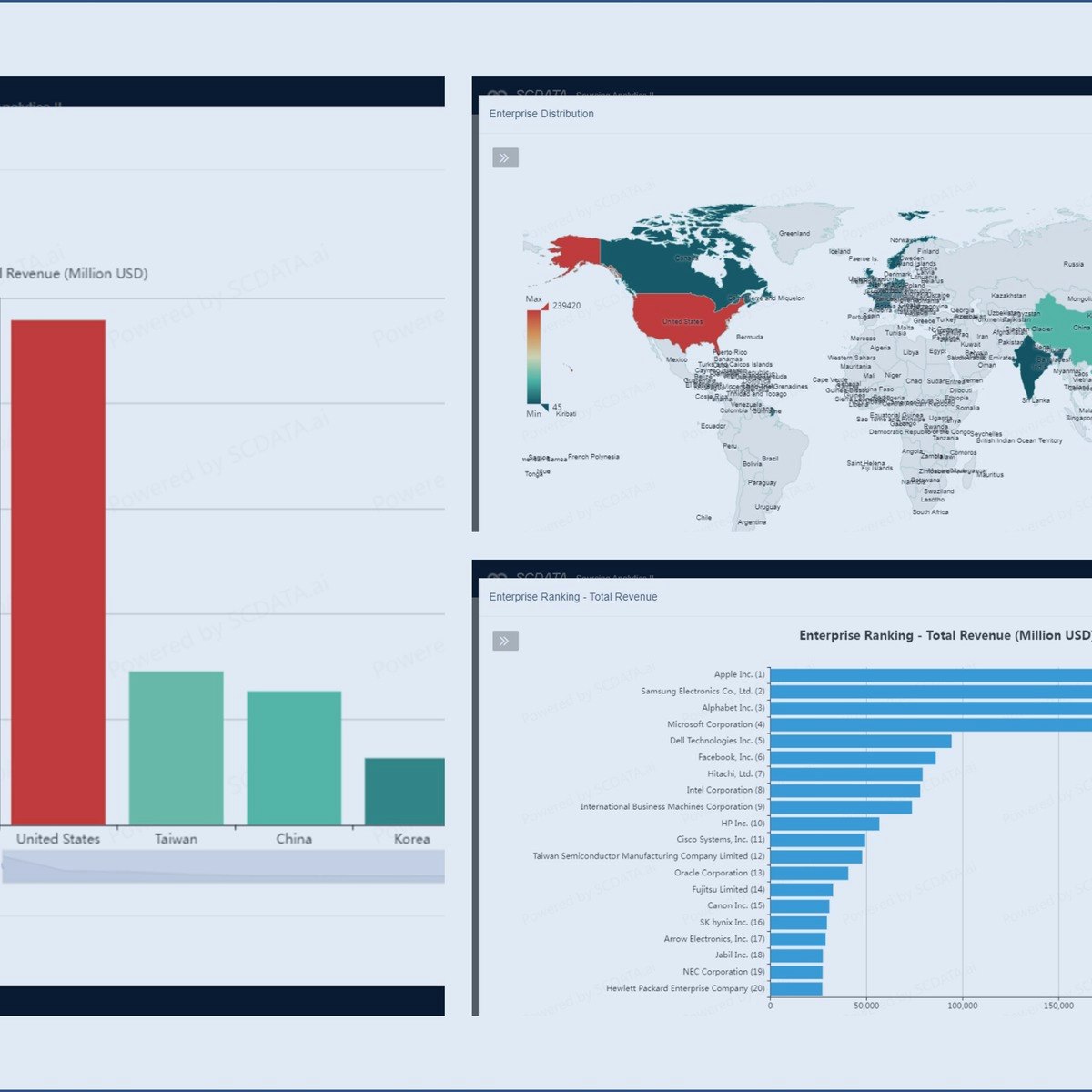
Sourcing Analytics
It is easy to spend money, but hard to get the value.
From 2007 to 2010, Apple made $27 billion from iPhone with a profit of $15.6 billion. Apple could not achieve this success without its global sourcing strategy. However, one of Apple’s key suppliers, Samsung Electronics, became a competitor and used its cost advantage to over-take Apple in the global market. Meanwhile, many new suppliers and products are emerging constantly. To continue the success, Apple must explore the global markets to identify and select new suppliers that are capable, inexpensive and financially robust. The question is, how to do it right for this year?
What Apple experienced is typical in practice, as a company may have thousands of suppliers, and numerous new suppliers and products / services emerge constantly and globally, which requires a frequent adjustment of the supply base.
In this course, you will learn sourcing analytics which applies data analytics and business intelligence to supplier development and management. Specifically, you will learn market intelligence, bargain power analysis, and supplier analysis, to identify and select suppliers with the objective of getting more value with less spend.
Fundamentals of Cloud Computing
This course is the second of a series that aims to prepare you for a role working in data analytics. In this course, you will be introduced to many of the core concepts of cloud computing. You will learn about the primary deployment models. We’ll go through the common cloud computing service models. The hands on material offers the opportunity to review and configure a cloud account. This course covers a wide variety of topics that are critical for understanding cloud computing and are designed to give you an introduction and overview as you begin to build relevant knowledge and skills.
Where, Why, and How of List Comprehension in Python
At the end of this project, you will learn about the Where, Why, and How of List Comprehension in Python. We are going to start with a quick introduction to lists and then we will talk about what list comprehension is and how and where we can use it. In the final task, we will load a JSON dataset containing information about UFO observations reported by civilians around the globe. we are going to use list comprehension to extract useful information out of our data.
Data Analytics in Sports Law and Team Management
This course provides an introduction to the fundamental ideas in applying data analytics to issues surrounding key regulatory and management functions within the sports industry. Sports as an industry is increasingly relying on data analytics for more effective deployment of resources and assessment of performance in areas ranging from player productivity to fan engagement, talent identification and development, coaching, sponsorship, and marketing. This course and its successors will help you understand this new role of data analysis in the sports business.
Introduction to Topic Modelling in R
By the end of this project, you will know how to load and pre-process a data set of text documents by converting the data set into a document feature matrix and reducing it’s dimensionality. You will also know how to run an unsupervised machine learning LDA topic model (Latent Dirichlet Allocation). You will know how to plot the change in topics over time as well as explore the distribution of topic probability in each document.
Predicting Credit Card Fraud with R
Welcome to Predicting Credit Card Fraud with R. In this project-based course, you will learn how to use R to identify fraudulent credit card transactions with a variety of classification methods and use R to generate synthetic samples to address the common problem of classification bias for highly imbalanced datasets—the class of interest (fraud) represents less than 1% of the observations.
Class imbalance can make it difficult to detect the effect independent variables have on fraud, ultimately leading to higher misclassification rates. Fixing the imbalance allows the minority class (fraud) to be better learned by the classifier algorithms.
After completing the project, you will be able to apply the methods introduced in the project to a wide range of classification problems that typically confront class imbalance, including predicting loan default, customer churn, cancer diagnosis, early high school dropout risk, and malware detection.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Data Mining Pipeline
This course introduces the key steps involved in the data mining pipeline, including data understanding, data preprocessing, data warehousing, data modeling, interpretation and evaluation, and real-world applications.
Data Mining Pipeline can be taken for academic credit as part of CU Boulder’s Master of Science in Data Science (MS-DS) degree offered on the Coursera platform. The MS-DS is an interdisciplinary degree that brings together faculty from CU Boulder’s departments of Applied Mathematics, Computer Science, Information Science, and others. With performance-based admissions and no application process, the MS-DS is ideal for individuals with a broad range of undergraduate education and/or professional experience in computer science, information science, mathematics, and statistics. Learn more about the MS-DS program at https://www.coursera.org/degrees/master-of-science-data-science-boulder.
Course logo image courtesy of Francesco Ungaro, available here on Unsplash: https://unsplash.com/photos/C89G61oKDDA
Data science perspectives on pandemic management
The COVID-19 pandemic is one of the first world-wide scenarios where data made a difference in capturing and analyzing the diffusion and impact of the disease.
We offer an introductory course for decision makers, policy makers, public bodies, NGOs, and private organizations about methods, tools, and experiences on the use of data for managing current and future pandemic scenarios.
This course describes modern methods for data-driven policy making in the context of pandemics. Discussed methods include policy making, innovation, and technology governance; data collection from citizens, crowdsourcing, gamification, and game with a purpose (GWAP); crowd monitoring and sensing; mobility and traffic analysis; disinformation and fake news impacts; and economical and financial impacts and sustainability models. Methods, tools, and analyses are presented to demonstrate how data can help in designing better solutions to pandemics and world-wide critical events.
In this course you will discover the role of policy making and technology governance for managing pandemics.
You will learn about methods like crowdsourcing, gamification, sensing of crowds and built environments, and contact tracing for understanding the dynamics of the pandemic.
You will understand the risk of disinformation and its impact on people perception and decisions.
The course also covers the financial models that describe the pandemic monetary impact on individuals and organizations, as well as the financial sustainability models that can be defined.
Thanks to this course you will get a deeper understanding of motivations, perceptions, choices, and actions of individuals in a pandemic setting, and you will be able to start defining appropriate mitigation actions.
This course was developed by a set of European research and education institutions as part of the research project 'Pan-European Response to the Impacts of the COVID-19 and future Pandemics and Epidemics' (PERISCOPE, https://www.periscopeproject.eu/). Funded by the European Commission Research Funding programme Horizon 2020 under the Grant Agreement number 101016233, PERISCOPE investigates the broad socio-economic and behavioural impacts of the COVID-19 pandemic, to make Europe more resilient and prepared for future large-scale risks.
Relational Database Support for Data Warehouses
Relational Database Support for Data Warehouses is the third course in the Data Warehousing for Business Intelligence specialization. In this course, you'll use analytical elements of SQL for answering business intelligence questions. You'll learn features of relational database management systems for managing summary data commonly used in business intelligence reporting. Because of the importance and difficulty of managing implementations of data warehouses, we'll also delve into storage architectures, scalable parallel processing, data governance, and big data impacts. In the assignments in this course, you can use either Oracle or PostgreSQL.
Popular Internships and Jobs by Categories
Browse
© 2024 BoostGrad | All rights reserved