
Back to Courses







Algorithms Courses - Page 22
Showing results 211-220 of 326
Data Structures
A good algorithm usually comes together with a set of good data structures that allow the algorithm to manipulate the data efficiently. In this online course, we consider the common data structures that are used in various computational problems. You will learn how these data structures are implemented in different programming languages and will practice implementing them in our programming assignments. This will help you to understand what is going on inside a particular built-in implementation of a data structure and what to expect from it. You will also learn typical use cases for these data structures.
A few examples of questions that we are going to cover in this class are the following:
1. What is a good strategy of resizing a dynamic array?
2. How priority queues are implemented in C++, Java, and Python?
3. How to implement a hash table so that the amortized running time of all operations is O(1) on average?
4. What are good strategies to keep a binary tree balanced?
You will also learn how services like Dropbox manage to upload some large files instantly and to save a lot of storage space!
Dynamic Programming, Greedy Algorithms
This course covers basic algorithm design techniques such as divide and conquer, dynamic programming, and greedy algorithms. It concludes with a brief introduction to intractability (NP-completeness) and using linear/integer programming solvers for solving optimization problems. We will also cover some advanced topics in data structures.
Dynamic Programming, Greedy Algorithms can be taken for academic credit as part of CU Boulder’s Master of Science in Data Science (MS-DS) degree offered on the Coursera platform. The MS-DS is an interdisciplinary degree that brings together faculty from CU Boulder’s departments of Applied Mathematics, Computer Science, Information Science, and others. With performance-based admissions and no application process, the MS-DS is ideal for individuals with a broad range of undergraduate education and/or professional experience in computer science, information science, mathematics, and statistics. Learn more about the MS-DS program at https://www.coursera.org/degrees/master-of-science-data-science-boulder.
C++ Data Structures in the STL
In this project you will read weather data from a file and populate a C++ Vector with the file data. The data is then uniquified in a Set data structure and stored in a Map for accessing data by year.
C++'s standard template library or STL contains data structures or containers that are built for efficiency. They are used to store and retrieve data in various formats. A list such as a Vector can be used in place of an array to contain data where the size cannot be determined ahead of time. A List is like a Vector, except elements can be more quickly added and deleted from it, since no shifting needs to occur. A Map is used to quickly look up a value based on a key rather than a numerical index, for example, to look up a phone number based on a key containing a person's name. A Set may be used to remove duplicates from a list, simply by assigning the data to it.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Deploy an Auto-Scaling HPC Cluster with Slurm
This is a self-paced lab that takes place in the Google Cloud console. In this lab, you will learn how to provision a dynamically scalable HPC cluster using Google Compute Engine, Google Deployment Manager, and the Slurm Workload Manager.
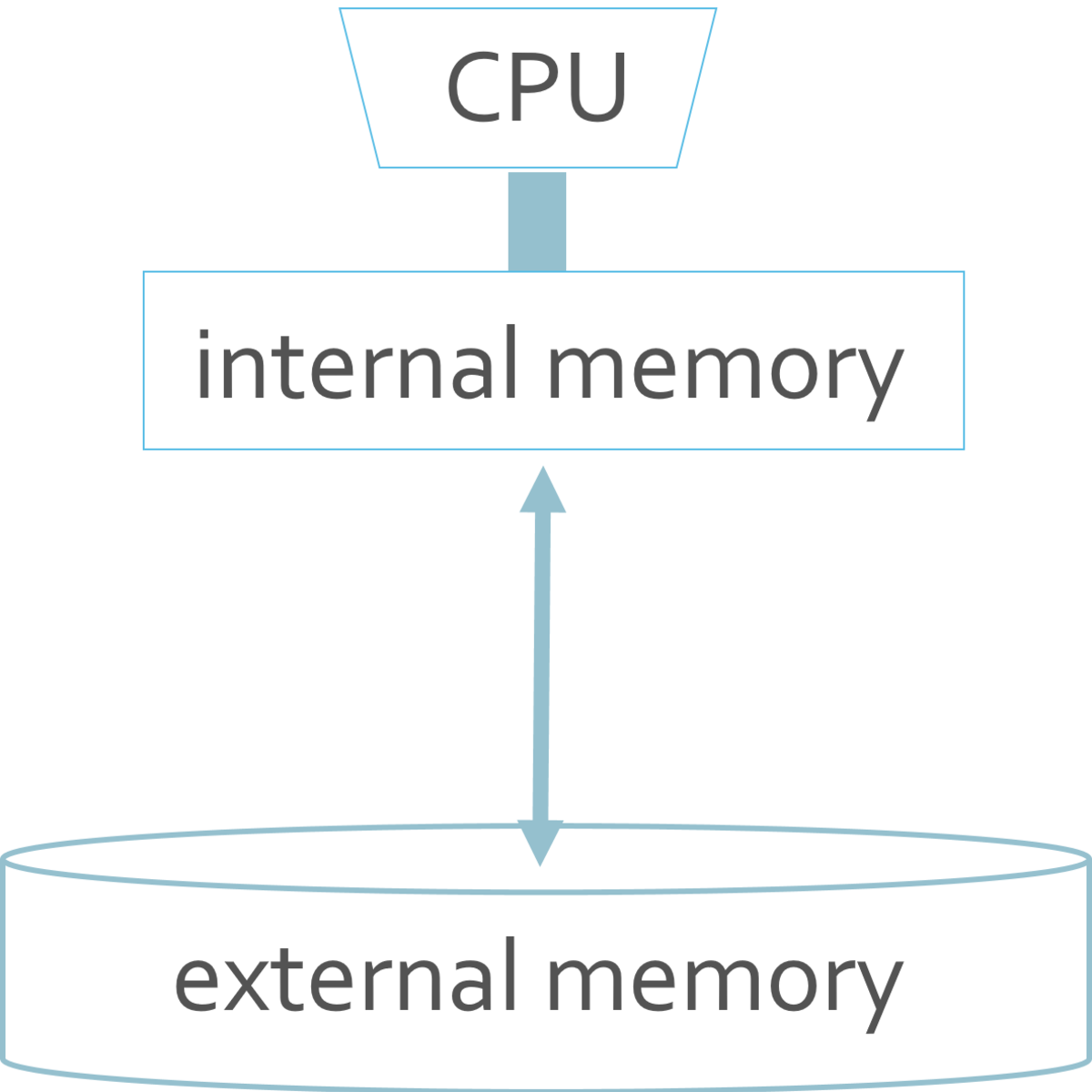
I/O-efficient algorithms
Operations on data become more expensive when the data item is located higher in the memory hierarchy. An operation on data in CPU registers is roughly a million times faster than an operation on a data item that is located in external memory that needs to be fetched first. These data fetches are also called I/O operations and need to be taken into account during the design of an algorithm. The goal of this course is to become familiar with important algorithmic concepts and techniques needed to effectively deal with such problems. We will work with a simplified memory hierarchy, but the notions extend naturally to more realistic models.
Prerequisites:
In order to successfully take this course, you should already have a basic knowledge of algorithms and mathematics. Here's a short list of what you are supposed to know:
- O-notation, Ω-notation, Θ-notation; how to analyze algorithms
- Basic calculus: manipulating summations, solving recurrences, working with logarithms, etc.
- Basic probability theory: events, probability distributions, random variables, expected values etc.
- Basic data structures: linked lists, stacks, queues, heaps
- (Balanced) binary search trees
- Basic sorting algorithms, for example MergeSort, InsertionSort, QuickSort
- Graph terminology, representations of graphs (adjacency lists and adjacency matrix), basic graph algorithms (BFS, DFS, topological sort, shortest paths)
The material for this course is based on the course notes that can be found under the resources tab. We will not cover everything from the course notes. The course notes are there both for students who did not fully understand the lectures as well as for students who would like to dive deeper into the topics.
The video lectures contain a few very minor mistakes. A list of these mistakes can be found under resources. If you think you found an error, report a problem by clicking the square flag at the bottom of the lecture or quiz where you found the error.
Analyze Datasets and Train ML Models using AutoML
In the first course of the Practical Data Science Specialization, you will learn foundational concepts for exploratory data analysis (EDA), automated machine learning (AutoML), and text classification algorithms. With Amazon SageMaker Clarify and Amazon SageMaker Data Wrangler, you will analyze a dataset for statistical bias, transform the dataset into machine-readable features, and select the most important features to train a multi-class text classifier. You will then perform automated machine learning (AutoML) to automatically train, tune, and deploy the best text-classification algorithm for the given dataset using Amazon SageMaker Autopilot. Next, you will work with Amazon SageMaker BlazingText, a highly optimized and scalable implementation of the popular FastText algorithm, to train a text classifier with very little code.
Practical data science is geared towards handling massive datasets that do not fit in your local hardware and could originate from multiple sources. One of the biggest benefits of developing and running data science projects in the cloud is the agility and elasticity that the cloud offers to scale up and out at a minimum cost.
The Practical Data Science Specialization helps you develop the practical skills to effectively deploy your data science projects and overcome challenges at each step of the ML workflow using Amazon SageMaker. This Specialization is designed for data-focused developers, scientists, and analysts familiar with the Python and SQL programming languages and want to learn how to build, train, and deploy scalable, end-to-end ML pipelines - both automated and human-in-the-loop - in the AWS cloud.
Artificial Intelligence Ethics in Action
AI Ethics research is an emerging field, and to prove our skills, we need to demonstrate our critical thinking and analytical ability. Since it's not reasonable to jump into a full research paper with our newly founded skills, we will instead work on 3 projects that will demonstrate your ability to analyze ethical AI across a variety of topics and situations. These projects include all the skills you've learned in this AI Ethics Specialization.
Endless Runner Game using Unity Engine and C#
In this 1-hour long project-based course, you will learn how to build a fully functioning game using Unity engine and C# through learning about the environment in Unity, the game objects and the cameras. You will also be able to build a collision system, design the game and add more scenes, menus and music system to the game.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
BioData Processing
Can we communicate with other living beings besides animals?
For example, it is well known that plants and fungi are sentient creatures, but modern societies/humans seem to regard this fact as unworthy of much attention. Perhaps we do so because we lack a common language to establish such inter-realms communication.
In this hands-on project you will challenge this frontier by translating electric signals (BioData) from plants and fungi into audio-visual media that we humans are capable of relating to. In order to accomplish this, you will engage with Processing, "a flexible software sketchbook and a language for learning how to code within the context of the visual arts."
Optional: In case you have an Anduino kit this project can be double fun, as learners will have instructions on how to collect the BioData themselves.
Computers, Waves, Simulations: A Practical Introduction to Numerical Methods using Python
Interested in learning how to solve partial differential equations with numerical methods and how to turn them into python codes? This course provides you with a basic introduction how to apply methods like the finite-difference method, the pseudospectral method, the linear and spectral element method to the 1D (or 2D) scalar wave equation. The mathematical derivation of the computational algorithm is accompanied by python codes embedded in Jupyter notebooks. In a unique setup you can see how the mathematical equations are transformed to a computer code and the results visualized. The emphasis is on illustrating the fundamental mathematical ingredients of the various numerical methods (e.g., Taylor series, Fourier series, differentiation, function interpolation, numerical integration) and how they compare. You will be provided with strategies how to ensure your solutions are correct, for example benchmarking with analytical solutions or convergence tests. The mathematical aspects are complemented by a basic introduction to wave physics, discretization, meshes, parallel programming, computing models.
The course targets anyone who aims at developing or using numerical methods applied to partial differential equations and is seeking a practical introduction at a basic level. The methodologies discussed are widely used in natural sciences, engineering, as well as economics and other fields.
Popular Internships and Jobs by Categories
Browse
© 2024 BoostGrad | All rights reserved