Back to Courses







Data Analysis Courses - Page 59
Showing results 581-590 of 998
Big Data, Artificial Intelligence, and Ethics
This course gives you context and first-hand experience with the two major catalyzers of the computational science revolution: big data and artificial intelligence. With more than 99% of all mediated information in digital format and with 98% of the world population using digital technology, humanity produces an impressive digital footprint. In theory, this provides unprecedented opportunities to understand and shape society. In practice, the only way this information deluge can be processed is through using the same digital technologies that produced it. Data is the fuel, but machine learning it the motor to extract remarkable new knowledge from vasts amounts of data. Since an important part of this data is about ourselves, using algorithms in order to learn more about ourselves naturally leads to ethical questions. Therefore, we cannot finish this course without also talking about research ethics and about some of the old and new lines computational social scientists have to keep in mind. As hands-on labs, you will use IBM Watson’s artificial intelligence to extract the personality of people from their digital text traces, and you will experience the power and limitations of machine learning by teaching two teachable machines from Google yourself.
Data Science Ethics
What are the ethical considerations regarding the privacy and control of consumer information and big data, especially in the aftermath of recent large-scale data breaches?
This course provides a framework to analyze these concerns as you examine the ethical and privacy implications of collecting and managing big data. Explore the broader impact of the data science field on modern society and the principles of fairness, accountability and transparency as you gain a deeper understanding of the importance of a shared set of ethical values. You will examine the need for voluntary disclosure when leveraging metadata to inform basic algorithms and/or complex artificial intelligence systems while also learning best practices for responsible data management, understanding the significance of the Fair Information Practices Principles Act and the laws concerning the "right to be forgotten."
This course will help you answer questions such as who owns data, how do we value privacy, how to receive informed consent and what it means to be fair.
Data scientists and anyone beginning to use or expand their use of data will benefit from this course. No particular previous knowledge needed.
Marketing Analytics
Organizations large and small are inundated with data about consumer choices. But that wealth of information does not always translate into better decisions. Knowing how to interpret data is the challenge -- and marketers in particular are increasingly expected to use analytics to inform and justify their decisions.
Marketing analytics enables marketers to measure, manage and analyze marketing performance to maximize its effectiveness and optimize return on investment (ROI). Beyond the obvious sales and lead generation applications, marketing analytics can offer profound insights into customer preferences and trends, which can be further utilized for future marketing and business decisions.
This course, developed at the Darden School of Business at the University of Virginia, gives you the tools to measure brand and customer assets, understand regression analysis, and design experiments as a way to evaluate and optimize marketing campaigns. You'll leave the course with a solid understanding of how to use marketing analytics to predict outcomes and systematically allocate resources.
You can follow my posts in Twitter, @rajkumarvenk, and on linkedin: https://www.linkedin.com/in/education-marketing.
Thanks,
Raj
Professor of Business Administration at Darden
Identifying Patient Populations
This course teaches you the fundamentals of computational phenotyping, a biomedical informatics method for identifying patient populations. In this course you will learn how different clinical data types perform when trying to identify patients with a particular disease or trait. You will also learn how to program different data manipulations and combinations to increase the complexity and improve the performance of your algorithms. Finally, you will have a chance to put your skills to the test with a real-world practical application where you develop a computational phenotyping algorithm to identify patients who have hypertension. You will complete this work using a real clinical data set while using a free, online computational environment for data science hosted by our Industry Partner Google Cloud.
Graduate Admission Prediction with Pyspark ML
In this 1 hour long project-based course, you will learn to build a linear regression model using Pyspark ML to predict students' admission at the university. We will use the graduate admission 2 data set from Kaggle. Our goal is to use a Simple Linear Regression Machine Learning Algorithm from the Pyspark Machine learning library to predict the chances of getting admission. We will be carrying out the entire project on the Google Colab environment with the installation of Pyspark. You will need a free Gmail account to complete this project. Please be aware of the fact that the dataset and the model in this project, can not be used in the real-life. We are only using this data for the learning purposes.
By the end of this project, you will be able to build the linear regression model using Pyspark ML to predict admission chances.You will also be able to setup and work with Pyspark on the Google Colab environment. Additionally, you will also be able to clean and prepare data for analysis.
You should be familiar with the Python Programming language and you should have a theoretical understanding of Linear Regression algorithm.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Cloud Composer: Qwik Start - Console
This is a self-paced lab that takes place in the Google Cloud console.
In this lab, you create a Cloud Composer environment using the GCP Console. You then use the Airflow web interface to run a workflow that verifies a data file, creates and runs an Apache Hadoop wordcount job on a Dataproc cluster, and deletes the cluster.
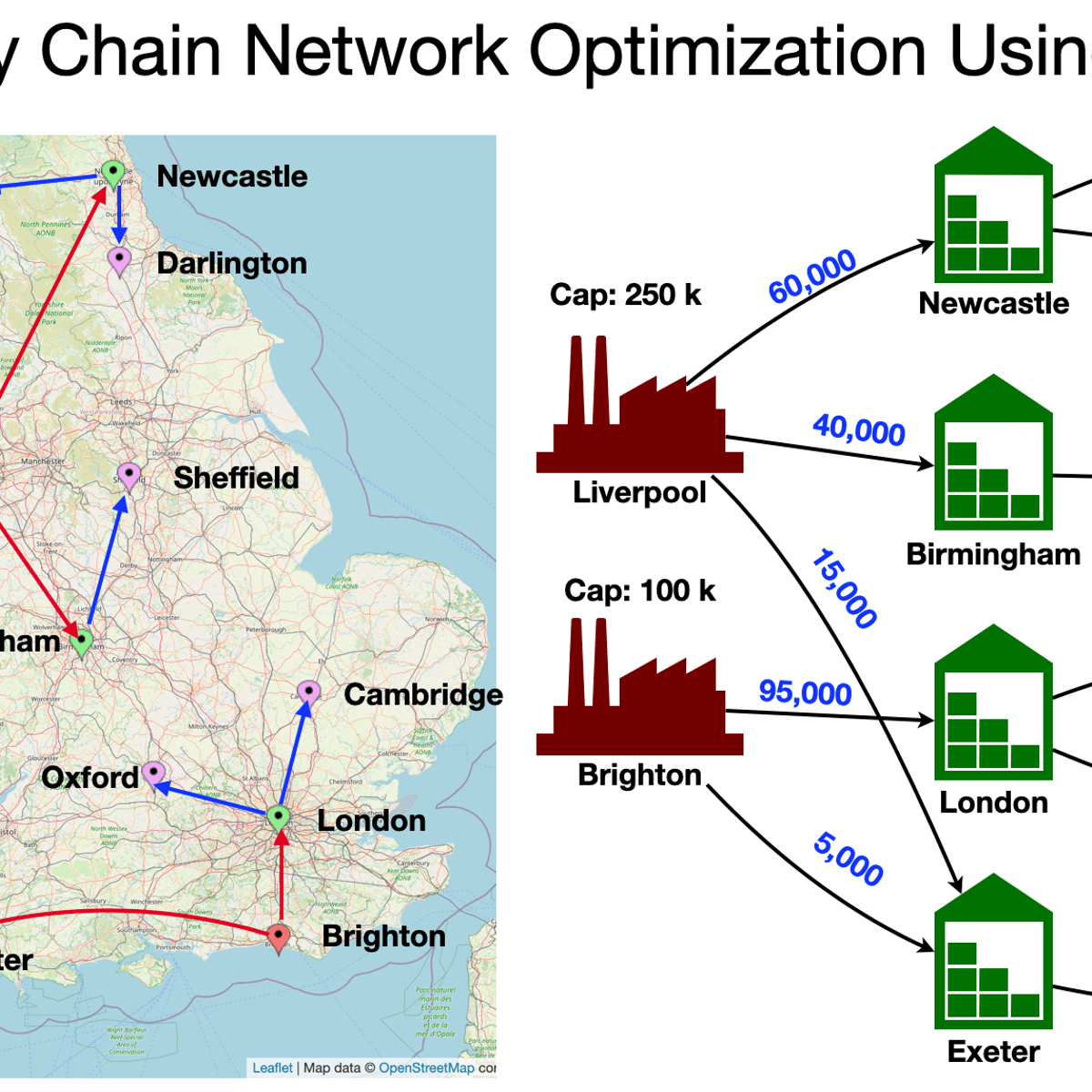
Supply Chain Network Optimization Using MILP on RStudio
Supply Chain Network Optimization
Understanding and Visualizing Data with Python
In this course, learners will be introduced to the field of statistics, including where data come from, study design, data management, and exploring and visualizing data. Learners will identify different types of data, and learn how to visualize, analyze, and interpret summaries for both univariate and multivariate data. Learners will also be introduced to the differences between probability and non-probability sampling from larger populations, the idea of how sample estimates vary, and how inferences can be made about larger populations based on probability sampling.
At the end of each week, learners will apply the statistical concepts they’ve learned using Python within the course environment. During these lab-based sessions, learners will discover the different uses of Python as a tool, including the Numpy, Pandas, Statsmodels, Matplotlib, and Seaborn libraries. Tutorial videos are provided to walk learners through the creation of visualizations and data management, all within Python. This course utilizes the Jupyter Notebook environment within Coursera.
Text Mining and Analytics
This course will cover the major techniques for mining and analyzing text data to discover interesting patterns, extract useful knowledge, and support decision making, with an emphasis on statistical approaches that can be generally applied to arbitrary text data in any natural language with no or minimum human effort.
Detailed analysis of text data requires understanding of natural language text, which is known to be a difficult task for computers. However, a number of statistical approaches have been shown to work well for the "shallow" but robust analysis of text data for pattern finding and knowledge discovery. You will learn the basic concepts, principles, and major algorithms in text mining and their potential applications.
Visualizing & Communicating Results in Python with Jupyter
Code and run your first Python program in minutes without installing anything!
This course is designed for learners with limited coding experience, providing a foundation for presenting data using visualization tools in Jupyter Notebook. This course helps learners describe and make inferences from data, and better communicate and present data.
The modules in this course will cover a wide range of visualizations which allow you to illustrate and compare the composition of the dataset, determine the distribution of the dataset, and visualize complex data such as geographically-based data. Completion of Data Analysis in Python with pandas & matplotlib in Spyder before taking this course is recommended.
To allow for a truly hands-on, self-paced learning experience, this course is video-free.
Assignments contain short explanations with images and runnable code examples with suggested edits to explore code examples further, building a deeper understanding by doing. You’ll benefit from instant feedback from a variety of assessment items along the way, gently progressing from quick understanding checks (multiple choice, fill in the blank, and un-scrambling code blocks) to small, approachable coding exercises that take minutes instead of hours. Finally, an accumulative lab at the end of the course will provide you an opportunity to apply all learned concepts within a real-world context.
Popular Internships and Jobs by Categories
Find Jobs & Internships
Browse





© 2024 BoostGrad | All rights reserved