Back to Courses






Data Science Courses - Page 41
Showing results 401-410 of 1407
Handling Imbalanced Data Classification Problems
In this 2-hour long project-based course on handling imbalanced data classification problems, you will learn to understand the business problem related we are trying to solve and and understand the dataset. You will also learn how to select best evaluation metric for imbalanced datasets and data resampling techniques like undersampling, oversampling and SMOTE before we use them for model building process. At the end of the course you will understand and learn how to implement ROC curve and adjust probability threshold to improve selected evaluation metric of the model.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Supervised Machine Learning: Classification
This course introduces you to one of the main types of modeling families of supervised Machine Learning: Classification. You will learn how to train predictive models to classify categorical outcomes and how to use error metrics to compare across different models. The hands-on section of this course focuses on using best practices for classification, including train and test splits, and handling data sets with unbalanced classes.
By the end of this course you should be able to:
-Differentiate uses and applications of classification and classification ensembles
-Describe and use logistic regression models
-Describe and use decision tree and tree-ensemble models
-Describe and use other ensemble methods for classification
-Use a variety of error metrics to compare and select the classification model that best suits your data
-Use oversampling and undersampling as techniques to handle unbalanced classes in a data set
Who should take this course?
This course targets aspiring data scientists interested in acquiring hands-on experience with Supervised Machine Learning Classification techniques in a business setting.
What skills should you have?
To make the most out of this course, you should have familiarity with programming on a Python development environment, as well as fundamental understanding of Data Cleaning, Exploratory Data Analysis, Calculus, Linear Algebra, Probability, and Statistics.
Linear Regression with Python
In this 2-hour long project-based course, you will learn how to implement Linear Regression using Python and Numpy. Linear Regression is an important, fundamental concept if you want break into Machine Learning and Deep Learning. Even though popular machine learning frameworks have implementations of linear regression available, it's still a great idea to learn to implement it on your own to understand the mechanics of optimization algorithm, and the training process.
Since this is a practical, project-based course, you will need to have a theoretical understanding of linear regression, and gradient descent. We will focus on the practical aspect of implementing linear regression with gradient descent, but not on the theoretical aspect.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Stock Analysis: Create a Buy Signal Filter using R and the Quantmod Package
In this 1-hour long project-based course, you will learn how to pull down Stock Data using the R quantmod package. You will also learn how to perform analytics and pass financial risk functions to the data.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Block.one: Getting Started with The EOSIO Blockchain
This is a self-paced lab that takes place in the Google Cloud console.
In this lab, you create a virtual machine (VM) to host an EOSIO blockchain.
The Economics of AI
The course introduces you to cutting-edge research in the economics of AI and the implications for economic growth and labor markets. We start by analyzing the nature of intelligence and information theory. Then we connect our analysis to modeling production and technological change in economics, and how these processes are affected by AI. Next we turn to how technological change drives aggregate economic growth, covering a range of scenarios including a potential growth singularity. We also study the impact of AI-driven technological change on labor markets and workers, evaluating to what extent fears about technological unemployment are well-founded. We continue with an analysis of economic policies to deal with advanced AI. Finally, we evaluate the potential for transformative progress in AI to lead to significant disruptions and study the problem of how humans can control highly intelligent AI algorithms.
Probabilistic Graphical Models 2: Inference
Probabilistic graphical models (PGMs) are a rich framework for encoding probability distributions over complex domains: joint (multivariate) distributions over large numbers of random variables that interact with each other. These representations sit at the intersection of statistics and computer science, relying on concepts from probability theory, graph algorithms, machine learning, and more. They are the basis for the state-of-the-art methods in a wide variety of applications, such as medical diagnosis, image understanding, speech recognition, natural language processing, and many, many more. They are also a foundational tool in formulating many machine learning problems.
This course is the second in a sequence of three. Following the first course, which focused on representation, this course addresses the question of probabilistic inference: how a PGM can be used to answer questions. Even though a PGM generally describes a very high dimensional distribution, its structure is designed so as to allow questions to be answered efficiently. The course presents both exact and approximate algorithms for different types of inference tasks, and discusses where each could best be applied. The (highly recommended) honors track contains two hands-on programming assignments, in which key routines of the most commonly used exact and approximate algorithms are implemented and applied to a real-world problem.
The Power of Machine Learning: Boost Business, Accumulate Clicks, Fight Fraud, and Deny Deadbeats
It's the age of machine learning. Companies are seizing upon the power of this technology to combat risk, boost sales, cut costs, block fraud, streamline manufacturing, conquer spam, toughen crime fighting, and win elections.
Want to tap that potential? It's best to start with a holistic, business-oriented course on machine learning – no matter whether you’re more on the tech or the business side. After all, successfully deploying machine learning relies on savvy business leadership just as much as it relies on technical skill. And for that reason, data scientists aren't the only ones who need to learn the fundamentals. Executives, decision makers, and line of business managers must also ramp up on how machine learning works and how it delivers business value.
And the reverse is true as well: Techies need to look beyond the number crunching itself and become deeply familiar with the business demands of machine learning. This way, both sides speak the same language and can collaborate effectively.
This course will prepare you to participate in the deployment of machine learning – whether you'll do so in the role of enterprise leader or quant. In order to serve both types, this course goes further than typical machine learning courses, which cover only the technical foundations and core quantitative techniques. This curriculum uniquely integrates both sides – both the business and tech know-how – that are essential for deploying machine learning. It covers:
– How launching machine learning – aka predictive analytics – improves marketing, financial services, fraud detection, and many other business operations
– A concrete yet accessible guide to predictive modeling methods, delving most deeply into decision trees
– Reporting on the predictive performance of machine learning and the profit it generates
– What your data needs to look like before applying machine learning
– Avoiding the hype and false promises of “artificial intelligence”
– AI ethics: social justice concerns, such as when predictive models blatantly discriminate by protected class
NO HANDS-ON AND NO HEAVY MATH. This concentrated entry-level program is totally accessible to business leaders – and yet totally vital to data scientists who want to secure their business relevance. It's for anyone who wishes to participate in the commercial deployment of machine learning, no matter whether you'll play a role on the business side or the technical side. This includes business professionals and decision makers of all kinds, such as executives, directors, line of business managers, and consultants – as well as data scientists.
BUT TECHNICAL LEARNERS SHOULD TAKE ANOTHER LOOK. Before jumping straight into the hands-on, as quants are inclined to do, consider one thing: This curriculum provides complementary know-how that all great techies also need to master. It contextualizes the core technology, guiding you on the end-to-end process required to successfully deploy a predictive model so that it delivers a business impact.
LIKE A UNIVERSITY COURSE. This course is also a good fit for college students, or for those planning for or currently enrolled in an MBA program. The breadth and depth of the overall three-course specialization is equivalent to one full-semester MBA or graduate-level course.
IN-DEPTH YET ACCESSIBLE. Brought to you by industry leader Eric Siegel – a winner of teaching awards when he was a professor at Columbia University – this curriculum stands out as one of the most thorough, engaging, and surprisingly accessible on the subject of machine learning.
VENDOR-NEUTRAL. This course includes illuminating software demos of machine learning in action using SAS products. However, the curriculum is vendor-neutral and universally-applicable. The contents and learning objectives apply, regardless of which machine learning software tools you end up choosing to work with.
Deploying an Open Source Cassandra™ Database using the GCP Marketplace
This is a self-paced lab that takes place in the Google Cloud console. In this lab you will deploy an Apache Cassandra™ database using using the GCP marketplace. You will connect to the database using CQL Shell and run some simple DDL commands to create a table, load some data and query it.
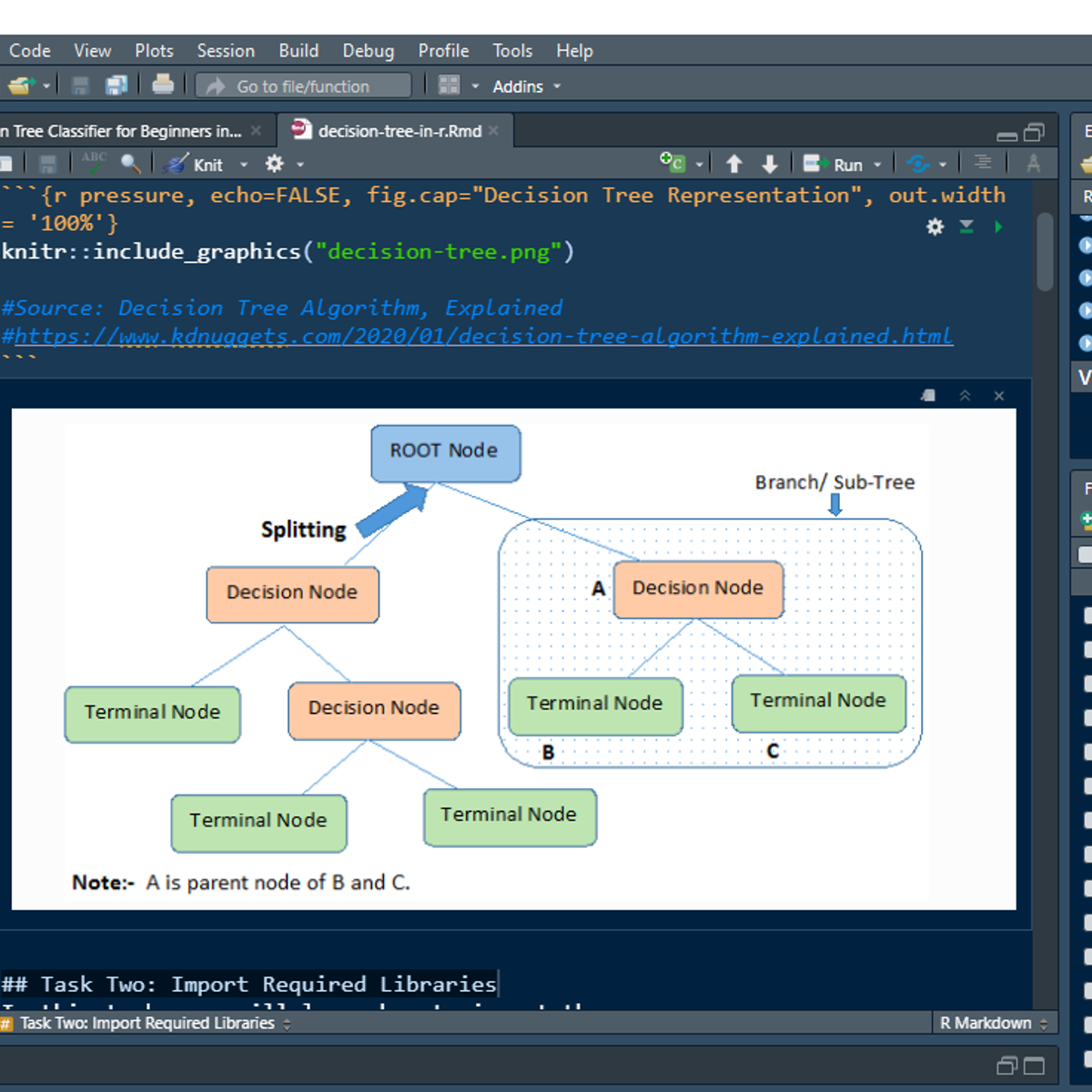
Decision Tree Classifier for Beginners in R
Welcome to this project-based course Decision Tree Classifier for Beginners in R. This is a hands-on project that introduces beginners to the world of statistical modeling. In this project, you will learn how to build decision tree models using the tree and rpart libraries in R. We will start this hands-on project by importing the Sonar data into R and exploring the dataset.
By the end of this 2-hour long project, you will understand the basic intuition behind the decision tree algorithm and how it works. To build the model, we will divide or partition the data into the training and testing data set. Finally, you will learn how to evaluate the model’s performance using metrics like Accuracy, Sensitivity, Specificity, F1-Score, and so on. By extension, you will learn how to save the trained model on your local system.
Although you do not need to be a data analyst expert or data scientist to succeed in this guided project, it requires a basic knowledge of using R, especially writing R syntaxes. Therefore, to complete this project, you must have prior experience with using R. If you are not familiar with working with using R, please go ahead to complete my previous project titled: “Getting Started with R”. It will hand you the needed knowledge to go ahead with this project on Decision Tree. However, if you are comfortable with working with R, please join me on this beautiful ride! Let’s get our hands dirty!
Popular Internships and Jobs by Categories
Find Jobs & Internships
Browse





© 2024 BoostGrad | All rights reserved