
Back to Courses








Machine Learning Courses - Page 23
Showing results 221-230 of 485
Multiple Linear Regression with scikit-learn
In this 2-hour long project-based course, you will build and evaluate multiple linear regression models using Python. You will use scikit-learn to calculate the regression, while using pandas for data management and seaborn for data visualization. The data for this project consists of the very popular Advertising dataset to predict sales revenue based on advertising spending through media such as TV, radio, and newspaper.
By the end of this project, you will be able to:
- Build univariate and multivariate linear regression models using scikit-learn
- Perform Exploratory Data Analysis (EDA) and data visualization with seaborn
- Evaluate model fit and accuracy using numerical measures such as R² and RMSE
- Model interaction effects in regression using basic feature engineering techniques
This course runs on Coursera's hands-on project platform called Rhyme. On Rhyme, you do projects in a hands-on manner in your browser. You will get instant access to pre-configured cloud desktops containing all of the software and data you need for the project. Everything is already set up directly in your internet browser so you can just focus on learning. For this project, this means instant access to a cloud desktop with Jupyter Notebooks and Python 3.7 with all the necessary libraries pre-installed.
Notes:
- You will be able to access the cloud desktop 5 times. However, you will be able to access instructions videos as many times as you want.
- This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
A Complete Reinforcement Learning System (Capstone)
In this final course, you will put together your knowledge from Courses 1, 2 and 3 to implement a complete RL solution to a problem. This capstone will let you see how each component---problem formulation, algorithm selection, parameter selection and representation design---fits together into a complete solution, and how to make appropriate choices when deploying RL in the real world. This project will require you to implement both the environment to stimulate your problem, and a control agent with Neural Network function approximation. In addition, you will conduct a scientific study of your learning system to develop your ability to assess the robustness of RL agents. To use RL in the real world, it is critical to (a) appropriately formalize the problem as an MDP, (b) select appropriate algorithms, (c ) identify what choices in your implementation will have large impacts on performance and (d) validate the expected behaviour of your algorithms. This capstone is valuable for anyone who is planning on using RL to solve real problems.
To be successful in this course, you will need to have completed Courses 1, 2, and 3 of this Specialization or the equivalent.
By the end of this course, you will be able to:
Complete an RL solution to a problem, starting from problem formulation, appropriate algorithm selection and implementation and empirical study into the effectiveness of the solution.
Machine/Deep Learning for Mining Quality Prediction-Enhanced
In this hands-on project, we will train machine learning and deep learning models to predict the % of Silica Concentrate in the Iron ore concentrate per minute. This project could be practically used in Mining Industry to get the % Silica Concentrate at much faster rate compared to the traditional methods.
Machine Teaching for Autonomous AI
Just as teachers help students gain new skills, the same is true of artificial intelligence (AI). Machine learning algorithms can adapt and change, much like the learning process itself. Using the machine teaching paradigm, a subject matter expert (SME) can teach AI to improve and optimize a variety of systems and processes. The result is an autonomous AI system.
In this course, you’ll learn how automated systems make decisions and how to approach building an AI system that will outperform current capabilities. Since 87% of machine learning systems fail in the proof-concept phase, it’s important you understand how to analyze an existing system and determine whether it’d be a good fit for machine teaching approaches. For your course project, you’ll select an appropriate use case, interview a SME about a process, and then flesh out a story for why and how you might go about building an autonomous AI system.
At the end of this course, you’ll be able to:
• Describe the concept of machine teaching
• Explain the role that SMEs play in training advanced AI
• Evaluate the pros and cons of leveraging human expertise in the design of AI systems
• Differentiate between automated and autonomous decision-making systems
• Describe the limitations of automated systems and humans in real-time decision-making
• Select use cases where autonomous AI will outperform both humans and automated systems
• Propose an autonomous AI solution to a real-world problem
• Validate your design against existing expertise and techniques for solving problems
This course is part of a specialization called Autonomous AI for Industry, which will launch in fall 2022.
PyCaret: Anatomy of Regression
In this 2 hour and 15 mins long project-based course, you will learn how to ow to set up PyCaret Environment and become familiar with the variety of data preparing tasks done during setup, be able to create, see and compare the performance of several models, learn how to tune your model without doing an exhaustive search, create impressive visuals of models, interpret models with the wrapper around SHAP Library and much more & all this with just a few lines of code.
Note: This project works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Deep Learning and Reinforcement Learning
This course introduces you to two of the most sought-after disciplines in Machine Learning: Deep Learning and Reinforcement Learning. Deep Learning is a subset of Machine Learning that has applications in both Supervised and Unsupervised Learning, and is frequently used to power most of the AI applications that we use on a daily basis. First you will learn about the theory behind Neural Networks, which are the basis of Deep Learning, as well as several modern architectures of Deep Learning. Once you have developed a few Deep Learning models, the course will focus on Reinforcement Learning, a type of Machine Learning that has caught up more attention recently. Although currently Reinforcement Learning has only a few practical applications, it is a promising area of research in AI that might become relevant in the near future.
After this course, if you have followed the courses of the IBM Specialization in order, you will have considerable practice and a solid understanding in the main types of Machine Learning which are: Supervised Learning, Unsupervised Learning, Deep Learning, and Reinforcement Learning.
By the end of this course you should be able to:
Explain the kinds of problems suitable for Unsupervised Learning approaches
Explain the curse of dimensionality, and how it makes clustering difficult with many features
Describe and use common clustering and dimensionality-reduction algorithms
Try clustering points where appropriate, compare the performance of per-cluster models
Understand metrics relevant for characterizing clusters
Who should take this course?
This course targets aspiring data scientists interested in acquiring hands-on experience with Deep Learning and Reinforcement Learning.
What skills should you have?
To make the most out of this course, you should have familiarity with programming on a Python development environment, as well as fundamental understanding of Data Cleaning, Exploratory Data Analysis, Unsupervised Learning, Supervised Learning, Calculus, Linear Algebra, Probability, and Statistics.
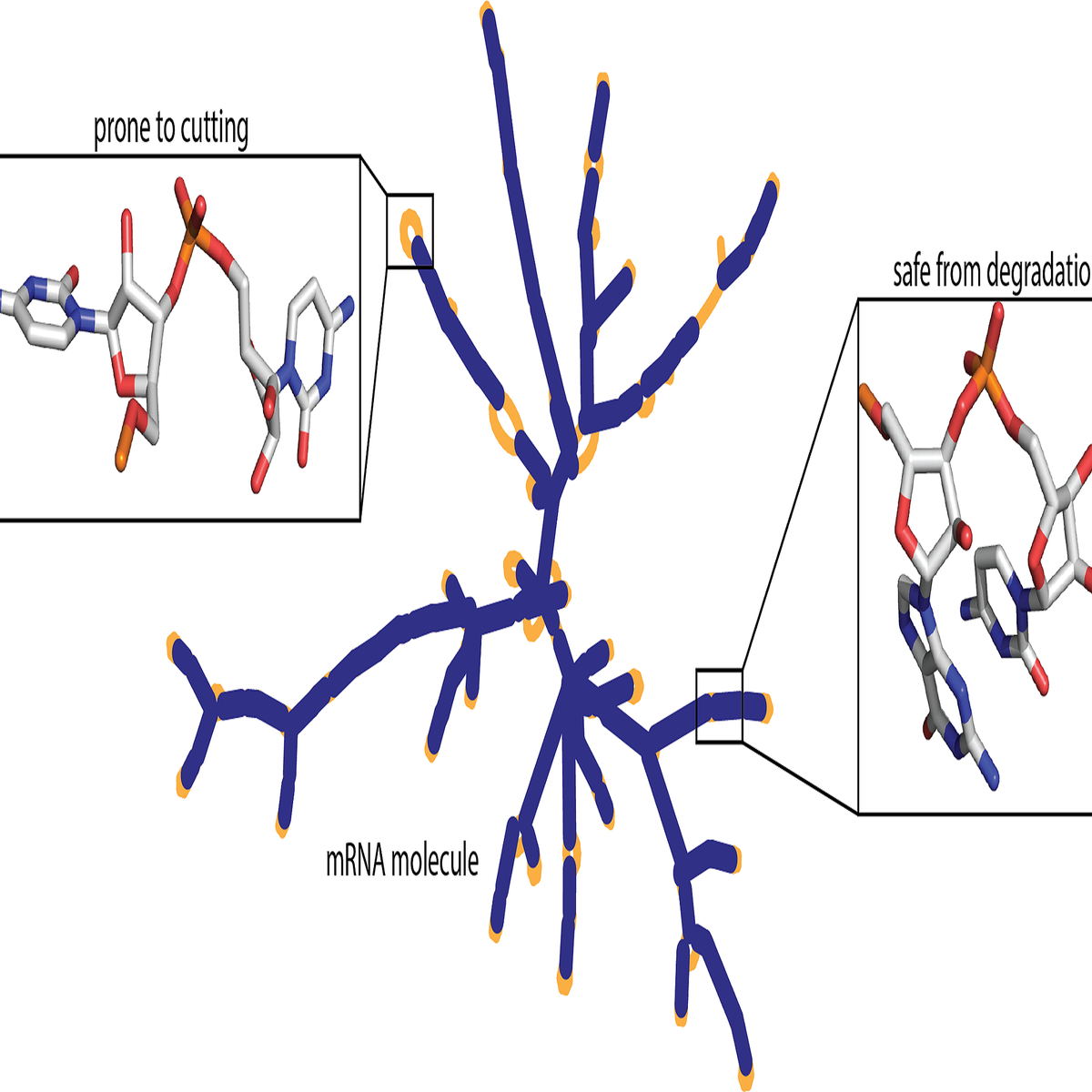
COVID-19 mRNA Vaccine Degradation Prediction
In this 2-hour long project-based course, you will learn how to predict mRNA Vaccine Degradation Rates at various positions of the molecule. Our model will predict likely degradation rates at each base of an RNA molecule which will be useful to develop models and design rules for RNA degradation.
We will look at how to build a Bidirectional Gated Recurrent Units Neural Network which can predict the degradation for multiple scenarios at each of the base.
We will cover how to train the model and evaluate on a test set. We will then finally make predictions using the trained model and compare it with the original degradation rates.
Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Deploy a Video Indexer Application using Azure Video Analyze
In this one-hour project, you will understand how Azure Video Analyzer works for video analysis and what information is generated for video indexing. You will learn how to deploy a simple Web Application that uses the Azure Video Analyzer SDK to upload and index videos to detect faces, labels in scenes, identify celebrities, and more.
Azure Video Analyzer is one of the most popular Artificial Intelligence services in the Azure ecosystem and is favored to analyze images and videos with confidence and low costs.
Once you're done with this project, you will be able to use Azure Video Analyzer to analyze and index your videos in just a few steps.
Image Segmentation with Python and Unsupervised Learning
In this one hour long project-based course, you will tackle a real-world problem in computer vision called segmentation. Segmentation means taking an image and partitioning it into different regions that capture the different elements of interest in the scene.
We will tackle this problem using an unsupervised learning technique called K-means.
By the end of this project, you will have segmented an image with unsupervised learning, using code you will write in Python.
Capstone Project: Advanced AI for Drug Discovery
In this capstone project course, we'll compare genome sequences of COVID-19 mutations to identify potential areas a drug therapy can look to target. The first step in drug discovery involves identifying target subsequences of theirs genome to target. We'll start by comparing the genomes of virus mutations to look for similarities. Then, we'll perform PCA to cut down our number of dimensions and identify the most common features. Next, we'll use K-means clustering in Python to find the optimal number of groups and trace the lineage of the virus. Finally, we'll predict similarity between the sequences and use this to pick a target subsequence. Throughout the course, each section will consist of a programming assignment coupled with a guide video and helpful hints. By the end, you'll be well on your way to discovering ways to combat disease with genome sequencing.
Popular Internships and Jobs by Categories
Browse
© 2024 BoostGrad | All rights reserved