
Cleaning and Exploring Big Data using PySpark
Overview
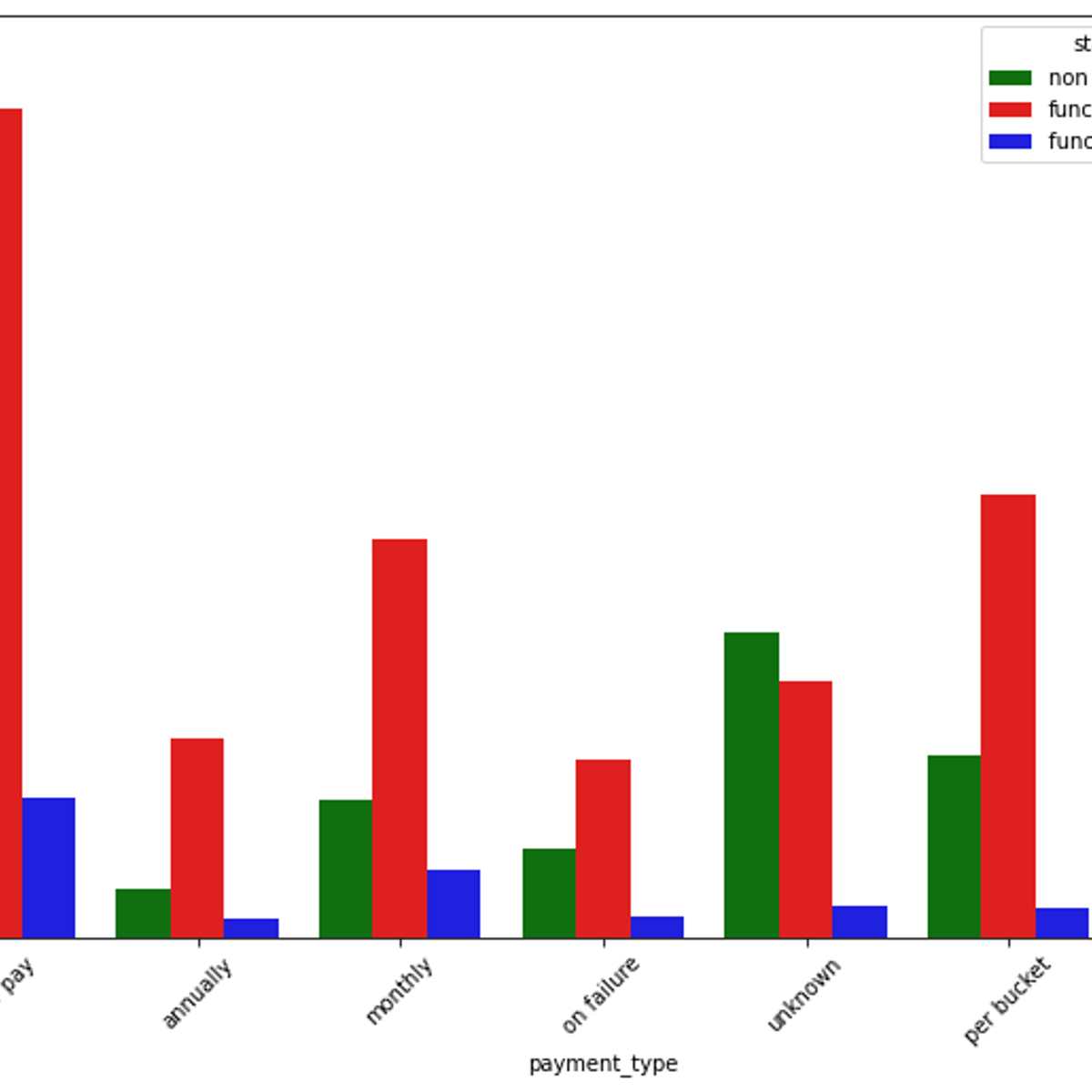
By the end of this project, you will learn how to clean, explore and visualize big data using PySpark. You will be using an open source dataset containing information on all the water wells in Tanzania. I will teach you various ways to clean and explore your big data in PySpark such as changing column’s data type, renaming categories with low frequency in character columns and imputing missing values in numerical columns. I will also teach you ways to visualize your data by intelligently converting Spark dataframe to Pandas dataframe. Cleaning and exploring big data in PySpark is quite different from Python due to the distributed nature of Spark dataframes. This guided project will dive deep into various ways to clean and explore your data loaded in PySpark. Data preprocessing in big data analysis is a crucial step and one should learn about it before building any big data machine learning model. Note: You should have a Gmail account which you will use to sign into Google Colab. Note: This course works best for learners who are based in the North America region. We’re currently working on providing the same experience in other regions.
Download the app